Outline#
In this week’s lab you will:
- Learn about
mmapand anonymous memory mapping - Learn about
errnoand error handling and propagation in C - Learn how to build a simple dynamic memory allocator using
mmap - Learn about implicit free lists and how to build a memory allocator using them from scratch
- Learn the intricacies of manual memory management and allocators
Preparation#
Open the lab5 directory in your local copy of your fork of the
lab pack 2 template repo in VS Code and continue on
with the lab.
If you don’t have a clone or fork of Lab Pack 2, go back to the lab 4 preparation section and follow the instructions.
Introduction#
In the previous labs and your first checkpoint, you have used the malloc and free functions from the C standard library to allocate heap memory dynamically. Specifically, the malloc() function returns a pointer to a block of memory, and the free() function subsequently frees the block. Under the hood, a dynamic memory allocator keeps track of allocated and free blocks of heap memory. In this lab, we will build our own implementation of malloc from scratch. We will first create a simple mmap allocator, which directs all allocate and free requests to mmap and munmap function calls. (We will explain these calls shortly.) We will then build a more memory-efficient single free-list allocator that will require more time and effort to manage the allocated and free blocks.
Virtual memory and dynamic memory allocators#
What is a dynamic memory allocator? A dynamic memory allocator manages an area of the process’s virtual memory known as the heap. We have already seen the memory map of a process’s virtual address space (with stack, heap, and other segments) a few times. Each process has the illusion of a privately owned address space with a specific layout (see below). The operating system and the CPU help translate virtual addresses to physical addresses. An allocator divides and maintains the heap as a collection of various-sized blocks. Each block is a contiguous chunk of virtual memory that is either allocated or free. By definition, an allocated block has been reserved by the application for use, and a free block is available for allocation. An allocated block remains allocated until it is free, and a free block remains free until it is allocated.
The figure below shows the virtual memory layout of a process in the Linux OS. The stack grows downward and the heap grows upward. For each process, the kernel maintains a variable brk (pronounced “break”) that points to the top of the heap.
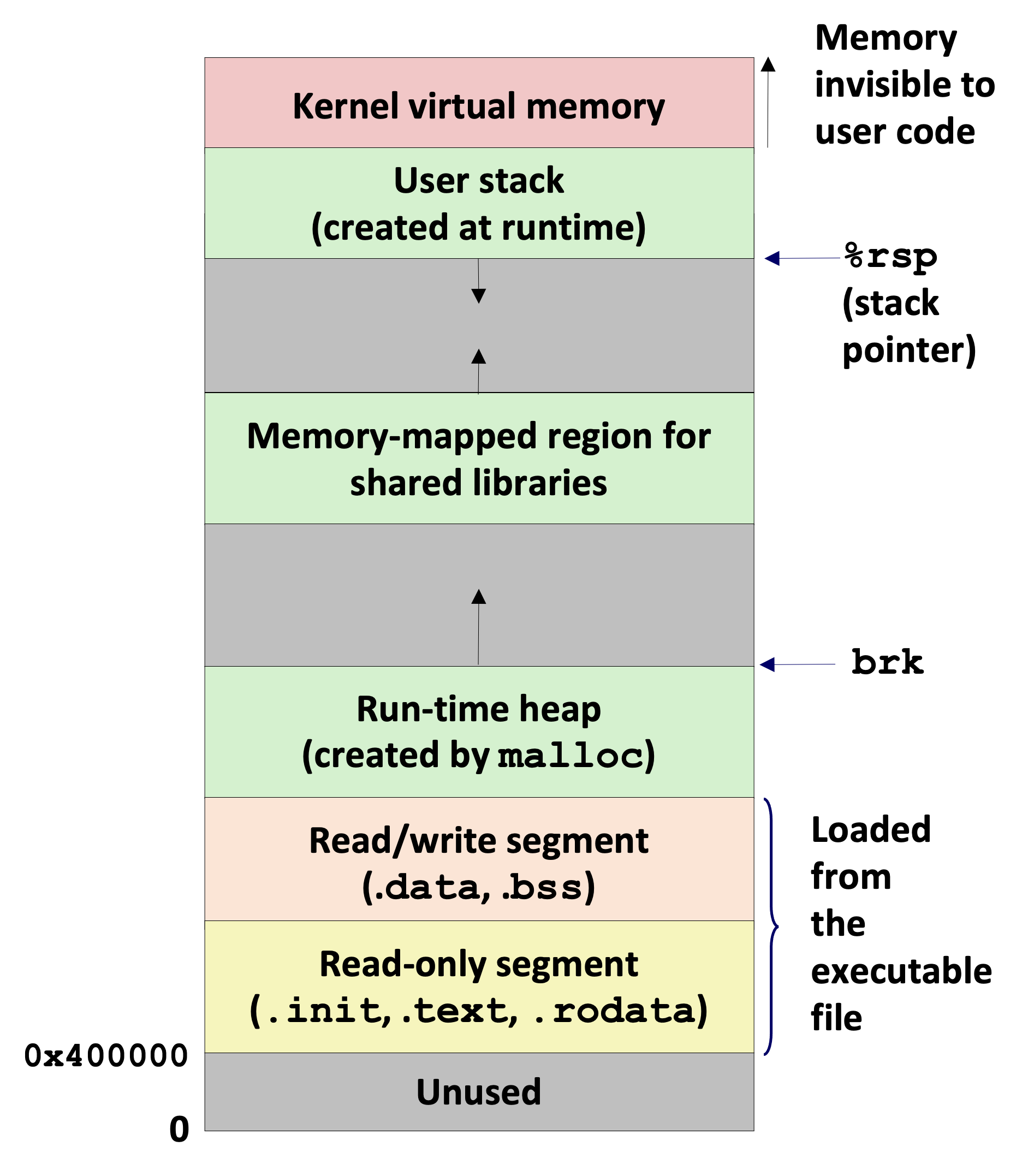
Basic setup#
The header file mymalloc.h in the repository provides the signature of the malloc and free functions.
Note that we have renamed the two functions as my_malloc and my_free.
This renaming is necessary to avoid conflicts with the C library’s malloc and
free functions.
These behave in the same way as malloc and free:
void *my_malloc(size_t size)is called when the user program wants to dynamically allocate a block of heap memory. The argument is thesize(in bytes) of the allocate request. The function should return a pointer pointing to the start of the allocated memory. The resultingstart addressshould be aligned to the nearest 8 bytes.void my_free(void *ptr)is for releasing/freeing a previously allocated block of memory. The argumentptris the start address of the allocated memory.
The size_t type#
You may have noticed the size_t type being used in the function declaration of
my_malloc. The sizes of data types in C are often platform dependent1.
Imagine if an int on a specific platform could only store 16 bits of
information — we would not be able to represent the value 100,000 (and more
critical to this lab, we could not allocate large arrays)!
The C specification therefore defines the size_t type in order to represent
the size of any object (including arrays). In other words: size_t is defined
as follows: “how many bytes does it take to reference a memory location on a specific architecture”.
Hence, the size of size_t is defined to be the same size as the CPU’s
architecture. On a 32-bit architecture, size_t consists of 4 bytes (32 bits)
and on a 64-bit architecture, it consists of 8 bytes (64 bits).
The sizeof(T) operator that you have seen previously returns a value of type
size_t, which is equal to the size in bytes of the given type T (if given
an expression instead of a type, it will be the size of the expression’s type).
For example: on most architectures storing an int takes four bytes, so
given size_t x = sizeof(int), the value of x will be 4.
The C specification defines another similar type: the ptrdiff_t type. This
type has the same size as size_t but is used to represent the difference
between two pointers of the same types.
For more information about size_t and ptrdiff_t you can run man size_t or
man ptrdiff_t in your terminals.
These may not be available on your specific system, so you can also look at the
relevant pages on the C Reference (size_t
and ptrdiff_t).
Now let’s get back to the lab!
In this lab, you are required to provide your own implementation of the
my_malloc() and my_free() functions. We provide a set of tests with a
testing script to check the correctness of your implementation.
Exercise 1: mmap-based allocator#
An mmap-based allocator simply directs the my_malloc and my_free calls to
the mmap / munmap function calls respectively. But what is “mmap” and “munmap”?
In simple terms, mmap is a system call that “loads” (read: “maps”) files
(e.g., stored on disk) into program’s virtual memory. The name “mmap” hence
comes from “memory map”.
Recall that main memory is byte-addressable and CPU has direct access to main memory (week 4 lectures) via load/store or mov instructions. Accessing files stored on disk drives requires a more elaborate mechanism involving the I/O bridge, the transfer of block-sized sectors between disks and memory, and interrupts. One way for the C program to access (i.e., read or write) a file on disk is to map the file into its virtual address space. The program can then use normal load/store instructions to access file contents. This process is called memory mapping. (The alternative mechanism to access disk files is to use read() and write() system calls that we will study later.)
So, if we provide a file to mmap as one of its arguments, then it returns a pointer to the start of file in memory. This is known as “memory-mapped file IO” or “file-backed IO” as we can now perform I/O operations by directly working on the file in memory (which is significantly faster than secondary storage). Behind the scenes, the operating system transparently loads the disk file into main memory. munmap is simply the reverse of mmap: it will “unload” (read: “unmap”) a previously mapped file.
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length);
The mmap function creates a new mapping in the virtual address space of the calling process and then maps the disk file pointed to by fd. (The file descriptor fd is an integer and serves a convenient way to work with files.) The starting address of the file is specified by addr (if addr is NULL, then the kernel will choose a page-aligned address). A page is a contiguous block (typically 4 KB) of virtual memory. A page is the basic unit of memory allocation inside the kernel. The length argument is the size of the mapping (it can be greater than the file size, and often is). The prot argument specifies what memory protection should be applied to the new mapping. The flags arguments determines whether updates to the mapping are visible to other processes (which may potentially be sharing the same region), and whether the updates are carried to the underlying file.
The munmap function deletes the mapping of the specified address range (specified with the addr and length arguments). The addr variable must be page-aligned.
Here is some good news after reading all that jargon! We do not necessarily need a file to use mmap. In fact, in this lab we will not mmap any files and instead we will use “anonymous mappings”. Anonymous mappings are not backed by any file on disk (so nothing is transferred from disk) and the requested memory is initialized to zero. Anonymous mapping is quite useful for building allocators as mmap provides a convenient interface with which we can request memory directly from the operating system. We will cover mmap (and file-backed IO) in much more detail in the lectures and a future lab. For the purposes of our lab, we will set prot = PROT_READ | PROT_WRITE (i.e. our process has read/write permissions on the new mapping), flags = MAP_PRIVATE | MAP_ANONYMOUS (i.e. the mapping is private to our process and is not backed by a file), fd = 0, and offset = 0.
As always, if you are interested in learning more about mmap and munmap then you can run man mmap (and man 2 mmap) to read about their specifics.
Getting started#
The src/mymalloc-mmap.c file in the lab 5 repository contains all the necessary definitions for our implementation:
#include "mymalloc-mmap.h"
void *my_malloc(size_t size) {
/** TODO */
return NULL;
}
void my_free(void *ptr) {
/** TODO **/
}
Allocating memory#
For this mmap allocator, if my_malloc is called to allocate N bytes, we
directly call mmap to allocate a chunk with size no less than N bytes.
Each mmap-ed chunk has a piece of meta-data memory for us to record the size
of the chunk. So later when we call munmap, we will always know the size of
the mmap-ed chunk.
Why is this meta-data important? Discuss amongst yourselves what would happen if this meta-data is omitted.
We first define the Chunk data structure, and set an appropriate maximum
allocation size we’re going to support, say, 16 MB. The Chunk data structure
simply keeps track of the size of the allocation it points to. We have provided
the following code for you in mymalloc-mmap.h:
// Chunk data structure
typedef struct {
size_t size;
} Chunk;
// Size of meta-data per Chunk
const size_t kMetadataSize = sizeof(Chunk);
// Maximum allocation size (16 MB)
const size_t kMaxAllocationSize = (16ull << 20) - kMetadataSize;
Note the ull suffix to the number 16 tells the compiler that the number is
an unsigned long long, that is to say, (at least) 64-bits. Then, we can
delegate the allocation request to mmap.
If we store the size of the mmap‘d block at the start of a Chunk, what
address should we return to the program? Should we return the start of the
Chunk? Is there any danger in doing this?
Implement the my_malloc function by calling mmap with the correct size and
the memory protection and mapping flags as described above.
Note: Remember to set the size of the allocation in the Chunk!
Fix the return value (if you haven’t already) of our my_malloc
implementation to return the address pointing to data correctly.
If you’ve read the man page for mmap, you will know that mmap can fail!
What should you return in the case when mmap fails to allocate more memory?
How can we inform a calling function that we’re out of memory?
Error handling and propagation#
C does not perform error handling by default. Instead, C programmers are supposed to carefully check every assumption and return value to make sure that they are not mistakenly working in an error state. Consider the case described above. What happens when the operating system is out of memory and mmap returns a value of MAP_FAILED?
C does not provide the programmer exceptions or error types to inform the calling function that execution is in an error state (or the kind of error state). In these cases, we expect mmap to inform the calling function of the type of _ error_ that has occurred by setting a global value known as the “errno” value. This errno value represents the “number of the last error”. Hence, if we get a MAP_FAILED pointer from mmap, we know an error has occurred, and we can check the kind of error by checking the errno value.
In the case of an out-of-memory error, mmap will set the errno value to ENOMEM, which signifies an out-of-memory error. To use errno, we have to include its header file as #include <errno.h> at the top of our file. A list of all the errors is enumerated in man errno.
Fix your implementation of my_malloc by checking the return value of mmap and returning MAP_FAILED if the mapping fails. Note: In this case we don’t have to set errno as mmap will have set it already. We will use errno directly in a later exercise.
Metadata reservation and mmap size#
Note that our my_malloc implementation is not fully correct yet. We still have to fix two major issues, namely:
- The chunk meta-data requires extra space in addition to the allocation size.
- The size passed to
mmapmust be a multiple of page size.
To solve these issues, we first add the allocation size to the chunk meta-data size, and then round it up to a multiple of page size. On most operating systems such as Windows and Linux the page size is 4 KB, but if you are using an ARM Mac, then the page size is 16 KB. Here we assume you are using Linux so the page size is 4 KB, i.e. 4096 bytes.
The function to round up an address to a particular alignment is given below. Note how we round up the allocation size using only bitwise operations.
inline static size_t round_up(size_t size, size_t alignment) {
const size_t mask = alignment - 1;
return (size + mask) & ~mask;
}
Now fix your my_malloc implementation using the round_up function by
ensuring we provision enough room for our meta-data and align to the page size.
Deallocating memory#
Now that our my_malloc function is (more-or-less) complete, let us now tackle implementing the my_free function.
What address is provided by the program to my_free? If it’s not the address we
got from mmap, how can we convert between the two?
Find the correct address to munmap by doing the inverse of what we did for
my_malloc. Implement my_free by passing this address and the mapped size to
munmap.
As with mmap, munmap can fail. We need to check the result of munmap and a
bort the execution of the program if we have encountered an error.
Why do we want to abort the program’s execution if we have encountered an error in munmap? What errors can we even encounter in my_free and munmap? Would anything go wrong if we continued execution? Hint: It depends on the kind of error! What would happen if we give a random address to my_free?
Fix the code by checking the return value of munmap, printing an error to stderr (using fprintf), and then aborting the program’s execution if unmapping the memory failed (using abort). Hint: You can convert errno to its respective string error by using the strerror(int errnum) function from the string standard library. Use #include <string.h> at the top of your source file to include it. You will also need to add #include <stdio.h> and #include <stdlib.h> to use the fprintf and abort functions.
Corner cases#
To be comprehensive, we need to resolve a few corner cases:
- For allocations with zero or greater than the maximum allocation size,
my_mallocshould returnNULL. In such cases, the user of themy_malloclibrary must check they aren’t using aNULLpointer by accident. - Freeing a
NULLpointer is a no-op.
Implement the two corner cases in my_malloc and my_free respectively.
Running Tests#
Compiling and testing your memory allocator(s) requires a slightly more complex
process that you’ve used previously. You should use the test.py python script
that is explained below as it handles a lot of this complexity for you.
After finishing the implementation of my_malloc and my_free, you need to
use the testing script to run tests. Testing is required to check the
correctness of your implementation.
$ python3 ./test.py
Other usages:
- Run a single test:
./test.py -t align. - Run tests with release build:
./test.py --release. A “release” build will enable more optimisations and not generate debug symbols. - Enable logging:
./test.py --log.- Use
LOG("Hello %s\n", "world");for logging in your source code.
- Use
- When you’re ready to move on to the implicit free list allocator, you will
need to tell the test script to compile the corresponding memory allocator.
This can be done by specifying
-m mymalloc-implicitas an argument.
Discuss amongst yourselves or with a tutor what limitations the mmap allocator
has. As a hint, think about how much memory mmap will use regardless of whether
the requested size is small.
Push your mymalloc-mmap.c code to your repository before continuing. The CI
will run the same test cases present in your local repository.
Exercise 2: Implicit Free List Allocator#
Most allocate requests from user programs are smaller than a page size. Therefore, always using mmap for allocations is not memory-efficient. Furthermore, the mmap-based allocator above basically delegates managing heap memory to the operating system. The resulting allocator makes an expensive system call for every allocation.
We will now use a global implicit free list to manage the memory on our own. But first: what is a “free list”?
Free Lists#
A free list is a data structure that keeps track of “ free “ blocks, i.e., they have not been reserved by the application and thus don’t have an active allocation. Free-list allocators are the backbone of modern C/C++ allocators.
There are two kinds of free lists:
- explicit free lists
- implicit free lists.
You can imagine an explicit free list to be a linked list where each node in the list points to the next free block. Free blocks are linked together with explicit pointers in the meta-data.
An implicit free list, on the other hand, is more subtle. Instead of pointing to the next free block, an implicit free list tracks whether a block is currently allocated or not (and its size). To find the next free block, we must iterate through all the blocks until we find one that is not currently allocated.
The figure below shows a 72-byte heap organized as an implicit free list. The
heap consists of four blocks after a number of malloc and free function
calls. To find a free block of appropriate size, the allocator needs to traverse
all blocks starting from the first block. The meta-data consists of a boolean
(allocated or not?) and block size. Next to the meta-data is the actual user
data (or “payload”).

We will focus on building an implicit free list in this Lab.
This will be implemented in mymalloc-implicit.c. To run the testing script
on the implicit free list allocator, rather than the mmap allocator you will
need to run it as:
python3 ./test.py -m mymalloc-implicit
Acquire initial memory#
To reduce the number of expensive system calls, we can get a large chunk of memory in one go and manage it on our own. Let us say we will acquire 64 MB of memory once from the operating system. We can then service allocation requests from the 64 MB chunk, and this chunk size is enough for most of our current tests.
Before we can acquire memory, we must think about how to represent a memory
block. Note that a “block” here is just a name for the allocation primitive we
will work with. That is to say, when we are asked to allocate an object in
my_malloc, we will allocate a “block” that contains meta-data followed by the
actual allocation. We define a Block to have two pieces of meta-data:
- Whether the
Blockis currently allocated or not - What is the allocation size of this
Block(including its meta-data size)
This metadata Block, alongside some useful constant values, has been defined
for you in the mymalloc-implicit.h header file:
typedef struct Block {
// Size of the block, including meta-data size.
size_t size;
// Is the block allocated or not?
bool allocated;
} Block;
// Size of meta-data per Block
const size_t kMetadataSize = sizeof(Block);
// Maximum allocation size (16 MB)
const size_t kMaxAllocationSize = (16ull << 20) - kMetadataSize;
// Memory size that is mmapped (64 MB)
const size_t kMemorySize = (16ull << 22);
You may recall that in Lab 1, we claimed there was no bool type in C, yet here we are using a bool. This is from the stdbool.h library and in fact, bool is defined as typedef int bool; it is just an alias for the int type. stdbool.h also provides the aliases false (meaning 0) and true (meaning 1). Depending on what you prefer, using these aliases may make code easier to read. Note that this also means a bool type stores 4 entire bytes even though it requires only 1 bit!
Why did we choose to represent the current state of the Block as a boolean
representing whether the Block is allocated or not? Why did we not choose to
represent the current state as whether it is free or not? (Note the subtle
difference in inverting the condition.) What benefits can we get if we represent
the boolean as allocated or not? Hint: think about what the default value of the field will be?
Acquire memory from the OS using mmap if we are allocating for the first time.
Use the same arguments for mmap as we used previously, aside from replacing the
size with kMemorySize.
Allocate memory from the global free list#
We use a global implicit free list to manage the memory blocks. Instead of adding explicit next/prev pointers to block meta-data, we use block start address and block size to traverse blocks inside a contiguous piece of memory and treat this as an implicit free list.
The only block meta-data we need to maintain is the free/allocated flag and the block size. For allocation, we traverse the list, find the first free block large enough, and split it into two blocks if necessary.
We fix the traversal order by always starting from the first block (i.e., the lowest address) and moving towards the last block (i.e., the highest address). To implement this traversal, we need to implement a function that will return the next block from a given block.
Before implementing a get_next_block function, complete the following two
helper functions:
is_free: This function returns1if the Block is free and0if not.block_size: This function returns the size of the given block.
You may be wondering why you need to implement these helper functions when
they seem to be quite trivial (assessing the members of the Block struct). As
you work through this lab and your first assignment, you will find having these
helper functions useful for breaking up your code (and for testing!).
Implement a function Block *get_next_block(Block *block) that returns the
next Block from a given Block. Be careful about the edge case where the given
Block is already the last block! In that case, you should return NULL.
Note that the size field in a Block will include the meta-data size.
Now that we have a function that can traverse through our free list, we need to find an algorithm for choosing an appropriate free block in which to place a newly allocated block. We will implement the first fit algorithm. First fit searches the free list from the beginning and chooses the first free block that fits. The idea is to traverse the free list until we find a Block large enough to fit our allocation. We may end up wasting memory if the chosen block is larger than the requested size. In that case, we may decide to split the block into two parts. We will worry about splitting later. If no Block can be found, we will return NULL.
Implement the core logic of finding a free block to allocate and returning it to the user in my_malloc using the get_next_block function by finding the first block large enough to fit our allocation request. Note: be careful about correctly setting the Block meta-data! We want to set the Block’s size to be equal to the actual size of the allocation + the meta-data per block. Just like the mmap allocator, we also need to be careful about what address we return to the program! Don’t forget to clear all the data in the Block by using memset() to write 0s to the data. This is very important from a security as well as correctness perspective as we don’t want to give garbage or previous values to the program.
At this point, we can return a block to the user, and in fact some of the tests will start to pass. However, to complete it, we need to implement splitting blocks, as currently after allocating the initial MMAPed chunk the program still only has one block to allocate; we will divide it up as necessary to satisfy allocation requests, only using the part of the chunk that requires using.
We want to be able to split a free block into two smaller blocks, with one Block just large enough to accommodate our allocation request. With what heuristic do you think we should split a large Block, i.e. how should we decide if a block is large enough to split?
Implement a function Block *split_block(Block *block, size_t size) that will split a given Block into two blocks with one of the Blocks having a size of size + kMetadataSize.
Using the split_block function above, implement splitting if the Block we select using the first-fit algorithm in my_malloc is too large. For simplicity, let’s set the heuristic to determine whether a Block is too large as if its size is greater-or-equal than the size of the allocation request + 2 \(\times\) the meta-data of a block (since we’re splitting the block into two) + the minimum allocation size (1 byte). We pick a simple heuristic like this as fine-tuning the splitting heuristic is a research topic and out of the scope of our course. Note: be careful not to set both blocks as allocated! Only one block is allocated to service the request.
If you’re feeling stuck understanding how split is meant to work, try drawing a “mini heap” on paper to visualise what happens to a block before and after it is split.
Releasing Memory#
To release a memory block, we get the block start address from the given pointer, and mark the block as free. It’s that simple!
Implement my_free by converting a given pointer to its block start address and
then marking it as free.
Alignment#
If you run all the tests now using ./test.py, you’ll see one important test
(align) failing. We see that it failed with a message
“align: tests/align.c:12: int main(): Assertion ‘is_word_aligned(ptr)’ failed.”.
Checking tests/align.c line 12, we can see that the first allocation
void *ptr = mallocing(1); may not return a word-aligned address.
You may find this test does not actually fail on your machine. Use the power of imagination to pretend you did encounter this issue, and fix it!
Think about why we may not be returning a word-aligned address? Hint: What is the heuristic with which we are splitting the blocks?
Fix our my_malloc implementation by properly returning addresses aligned to a word size (i.e. sizeof(size_t)). You can use the same round_up function as given above in the mmap allocator part of the lab. Run the tests again to see if the align test passes now. Hint: You may have to change the minimum allocation size from 1 B as well!
Handling corner cases (again)#
If you have gotten this far, congratulations! You now have a mostly correct implementation of an implicit free-list allocator. We just have to handle a few corner cases again just like for the mmap allocator.
Fix the my_malloc and my_free implementations by checking the corner cases just like with the mmap allocator.
Running tests#
After finishing the my_malloc and my_free implementations, rerun the tests to see if you are passing them or not. Note that all tests passing does not necessarily mean that your implementation is correct! Try making some small tests that use your my_malloc and my_free functions to allocate memory dynamically. Try to think of edge cases and other conditions that may break the assumptions of your implementation.
Remember to push your changes to mymalloc-implicit.c. The CI will run the
same tests as those present in your lab5/tests directory.
If you’ve made it this far, congratulations! The work you have done in this lab will make completing your first assignment much easier.
Additional Exercises#
We now have a fully functioning malloc/free implementation using implicit free lists. But there are a host of optimizations we can still perform! We list some advanced exercises to help you prepare for the first assignment, and we recommend trying them out!
Exercise 3: Linear Time Coalescing#
Over time, as programs allocate and free memory, we end up with a heap containing many small blocks. Finally, when all the blocks in the implicit free list are small, the allocator can no longer fit large allocations. For example, consider the heap in the figure we show above. If the user requests a 24-byte block, the allocator cannot fulfill the request even though 24 bytes of free memory are available on the heap. In this exercise, we ask you to implement linear time coalescing of free blocks to reduce heap fragmentation.
Hint: Traverse the list starting from the first block and coalesce all consecutive free blocks.
Exercise 4: Policies for Linear Time Coalescing#
Coalescing can happen at any point in time. For example, the allocator can traverse the heap and coalesce before or after malloc/free calls. In this exercise, we ask you to experiment with different coalescing policies. Your implementation should decouple the coalescing mechanism from the coalescing policies. Once the base mechanism is implemented (e.g., as a function) and is fixed, you should then be able to test a large number of policies. The mechanism dictates how you coalesce free blocks, and the policy dictates when you coalesce them.
Hints: Suppose you have a function coalesce() that can coalesce all the consecutive free blocks. You can then try the following policies:
coalesce()once after eachfreecoalesce()once every 10 `frees (or some other frequency)
Which do you think will have better performance?
Exercise 5: Constant Time Coalescing#
As a final exercise, we ask you to try coalescing free blocks in constant time instead of linear time.
Maintain the invariant that after each free, the heap should contain no
consecutive free blocks. To ensure the invariant, at the end of free(), you
may need to coalesce the freed block with both its left and right neighbour.
Finding the right neighbour starting address can be done by finding the current
block’s end address: address(block) + metadata(block)->size. But how can we
find the starting address of the left neighbour?
-
For example: If you are using Windows and tried compiling and running C code outside of WSL, you may have noticed
sizeof(long)is 4 bytes rather than 8. ↩