Outline#
In this week’s lab, you will:
- Learn the system calls for file I/O in Linux
- Learn the concept of standard I/O streams, and learn about file I/O utilities in the C standard I/O library
- Understand the typical uses and advantages of file streams
- Understand the uses and advantages of memory mapped I/O and the mmap() system call
- Practice the uses of file I/O and mmap() by writing some interesting C programs
Preparation#
This lab uses a new repository, make sure you fork and clone it!
Clone the lab pack 3 repo from here.
Introduction#
Input/Output (I/O): This specific tutorial covers file input/output (I/O) in C. You will learn how to read from and write to files stored on a storage device such as a disk drive. A file is a versatile abstraction on Unix-like systems. Many objects (including regular files containing user data, devices, and pipes for inter-process communication) are represented as files. We are concerned in this tutorial with the so-called regular files. A regular file contains bytes of data organized into a linear array called a byte stream. Linux does not impose any other structure on the files beyond the byte stream. Bytes may have value and represent anything from students’ marks to photos.
Today, we will do basic file operations such as open, close, read, and write. We will also learn two ways of performing read/write I/O on modern computer systems. The first method uses system calls for I/O (affectionately known as syscall I/O). The second method is memory-mapped I/O (or mmio for short). It uses the virtual memory abstraction and the operating system’s page faulting mechanism for performing I/O. The former is sometimes called explicit I/O because it explicitly uses system calls for reading and writing files. Mmio is also called implicit I/O because, from the programmer’s perspective, there is no distinction between accessing regular memory (i.e., allocated via malloc) and disk-resident files. In implicit I/O, both malloc’ed memory and files can be accessed via pointers, and pointer arithmetic works for both. Today, you will learn to perform this magic!
Somewhat annoyingly, we use disk, drive, storage, device, and storage device as alternative ways to refer to a canonical block device to distinguish it from byte-addressable main memory. Main memory is also referred to as physical memory or just memory or DRAM main memory.
Exercise 1: String Handling Revision#
This first exercise is a revision exercise for how string handling works in C. You first looked at implementing a few string utilities all the way back in Lab 1. Some of these functions are already included in the C standard library, but it’s good to practice doing them on your own!
In the file string_utils.c you will need to implement the following functions:
string_len: This function will return anintthat is the length of the given string.find_char: This function will return the index of the first occurrence of a given char.count_char: This function will return the number of times a given character appears in a string.split_string: This function will “split” a string along a given delimiter.
Remember to push your work to GitLab — the CI will test your implementation of these functions.
System Calls for File I/O#
We will use the most basic method of accessing files via read() and write()
system calls. Before a file can be read or written it must be opened via the
open() system call. Once the program is done using the file, it must be closed
via the close() system call.
Opening and Reading Files#
A file is opened via the open() system call.
int open (const char *pathname, int flags);
The open() system call returns a file descriptor (an integer) to make it easy
for the program to do operations on the file. The filepath and its name are only
needed for opening a file. The operating system kernel maintains a per-process
list of open files, called the file table. This table is indexed via file
descriptors (a.k.a., fds). An fds has an int type in C. Each Linux process has a
maximum number of files that it may open. File descriptors start at 0.
As an example, you can open a file somewhere in your home directory as follows:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
...
int fd;
fd = open ("/home/students/myfile", O_RDONLY);
Note that we have opened the file for reading only by specifying the O_RDONLY
flag. We can also open the file for writing only with O_WRONLY flag. Finally,
we can open the file for both reading and writing with the O_RDWR flag. You
can see the full list of flags with the man open command. You should try to
read about the flags: O_CREAT, O_APPEND, O_DIRECT, and O_SYNC.
If there is an error in opening a file, the open() system call returns -1.
Reading data from the file is done via the read() system call:
ssize_t read(int fd, void *buf, size_t len)
The system call reads the number of bytes specified by len into a buffer set
up by the program from an open file with descriptor fd (or -1 on error). The
buffer must be large enough to read the required number of bytes. On success,
the number of bytes written into buf is returned. The file position is
advanced by the number of bytes read from fd.
unsigned long word;
ssize_t nr;
nr = read (fd, &word, sizeof (unsigned long));
if (nr == -1)
/* error handling */
There are two problems with the above example.
- The
read()system call may return with less thanlenbytes. We will not delve into the full list of reasons for that scenario here, but common reasons are:- not enough bytes (i.e., equal to
len) are available - the system call is rudely interrupted for some reason.
- not enough bytes (i.e., equal to
- There is a possibility of return value of 0 when using
read(). A return value of 0 means the end-of-file (EOF) is reached.
Note that we need to handle the above two cases. We also need to handle any potential errors. The following code solves these problems:
ssize_t ret;
while (len != 0 && (ret = read (fd, buf, len)) != 0) {
if (ret == -1) {
if (errno = EINTR) /* interrupted */
continue;
perror("read");
break;
}
len -= ret;
buf += ret;
}
The loop reads len bytes from the current file position of fd into buf,
which should be len bytes in length. It continues reading until it reads all
len bytes, or until EOF is reached. Note the adjustments to len and buf
in the case more than zero, but less than len bytes are read.
perror prints a message on standard error.
What’s the deal with errno (again)?#
The C library provides support for detecting and reacting to errors in the execution of system calls. Below is a description of errno from the Linux manual page.
The <errno.h> header file defines the integer variable errno,
which is set by system calls and some library functions in the
event of an error to indicate what went wrong.
errno
The value in errno is significant only when the return value of
the call indicated an error (i.e., -1 from most system calls; -1
or NULL from most library functions); a function that succeeds is
allowed to change errno. The value of errno is never set to zero
by any system call or library function.
In our example code, EINTR means that a signal was received before any bytes
were read and the system call can be reissued.
Writing Files#
ssize_t write (int fd, const void *buf, size_t count);
As with reads, the most basic usage of the write system call is simple (see
below). We leave it to you to check for possible occurrence of partial writes
and errors.
const char *buf = "I am a good student!";
ssize_t nr;
nr = write(fd, buf, strlen(buf));
Closing Files#
After a program has finished working with a file descriptor, it can unmap (close) the file descriptor from the associated file via the close() system call.
int close (int fd);
Exercise 2: Echo a File#
Now that you know how to use the open, read, write and close system
calls to perform I/O on files, this is a simple warm-up exercise to practice
using them. The currently incomplete program provided in copy_file.c will take
two file names as command line arguments. The first of which is the source file
and the second the destination file. The main function which checks whether
the program has been given the correct number of arguments has been written for
you.
You will need to complete the copy_file function so that:
- It opens both files using
open. Make sure the appropriate flags are set for both calls — the source file should be open in read-only mode and the destination file in write-only mode. If either call toopenfails, use theperrorfunction to print an error and exit with return code1. - After opening both files, the
readsystem call should be used to read one character at a time in a loop fromsrc_fd. The return value of this function should be stored in the variablebytes_read. - After each call to
readthe value ofbytes_readshould be checked. If the end-of-file has been reached, the function should return. If an error has occurred, an error message should be printed usingperrorand the program should exit. - Otherwise, the single byte read should then be written to the destination
file using the
writesystem call. Store the return value inbytes_writtenand check this value for errors as well.
Complete the copy_file function in copy_file.c to match the above
specification. Remember to push your work to GitLab as the CI will run a simple
test of your program!
Click here to see a potential way you can structure your copy_file function.
void copy_file(const char *src_filename, const char *dst_filename) {
int src_fd, dst_fd;
ssize_t bytes_read, bytes_written;
char c;
/* Open both files */
src_fd = open(/* ... */);
dst_fd = open(/* ... */);
if (/* check for errors with `open` */) {
/* ... */
}
while (1) {
bytes_read = read(src_fd, &c, 1); /* read 1 byte */
if (/* check for errors with `read` */) {
/* ... */
}
if (bytes_read == 0) { /* EOF encountered */
break;
}
bytes_written = write(dst_fd, &c, 1); /* write 1 byte */
if (/* check for errors with `write` */) {
/* ... */
}
}
}
Is calling read and write to read/write one byte at a time efficient?
File Information Using fstat()#
Another system call that will be useful when performing I/O is fstat.
The fstat system call returns a number of different pieces of information
about the status of the file from the given file descriptor.
There is also the similar stat system call. The only difference to fstat is
that stat takes the name of the file as its first argument rather than a file
descriptor open to that file.
Update the code in copy_file.c so that it reads the file size of the source
file using the fstat system call. Use this information to reduce the number of
calls to read/write your code has to make.
Seeking with lseek()#
Each open file has an associated meta-data called the file position or offset. When the file is first opened, the file position is zero. Each read and write operation starts at a specific offset (current position). As bytes in the file are read from or written to (e.g., via read() and write() syscalls), the file offset advances accordingly.Typically, I/O occurs linearly through a file, and the file position updates automatically. Some applications may want to jump around (seek) in a file, accessing random locations. The lseek() system call sets the file position of a file descriptor to a given value. It performs no other action and initiates no I/O.
Read the description of lseek() from the manual page.
As an extension exercise, update the code in copy_file.c again so that is uses
lseek to find the size of the source file. Use this information to reduce the
number of calls to read/write your code has to make.
Page Caches and Buffering#
Storage devices such as disks and solid-state drives are much slower than byte-addressable main memory (DRAM). The operating system kernel maintains an in-memory data structure called the page cache that stores (caches) recently accessed files from disk. The page cache allows the kernel to fulfill subsequent read requests for the file content from memory, avoiding repeated disk accesses. Therefore, when you issue the read() system call in the above examples, the operating system first transfers file data from the disk into the page cache. It then copies data from the page cache to the user-specified buffer in the application memory. We call the data structure page cache because a page is the basic unit of memory allocation inside the kernel.
The kernel also optimizes write I/O operations by buffering them in the page cache. Imagine a program issuing a batch of small writes (e.g., 32 bytes). If the kernel accesses the slow disk on every write, then the system operates very inefficiently. Indeed, the kernel performs write buffering. When a program issues a write request, the data is copied into an in-memory buffer, and the buffer is marked dirty, denoting that the in-memory copy is newer than the disk-resident copy. Subsequent writes hit in the buffer, avoiding disk accesses again. At some point, the kernel decides to flush the dirty buffer(s) to disk. In modern Linux kernels, the page cache and the buffer subsystem have been unified as a single structure (page cache). Before Linux kernel 2.4, there was both a page cache and a buffer cache.
In summary, syscall I/O results in an extra copy from the kernel space to the user space (in addition to disk transfer). We refer to buffering in the page cache as kernel-level buffering.
File Streams#
To understand the motivation behind file streams, we need to briefly visit block devices and filesystem blocks.
Block Devices and Filesystem Blocks#
We consider storage devices, such as disks and solid-state drives (SSDs) block devices. The smallest addressable unit on a block device is the sector. We can access any (random) block. The sector is a physical attribute of the device (set at manufacturing time). Historically, disks have a typical sector size of 512 bytes. All I/O operations on a block device must occur at the granularity of one or more sectors. The other type of I/O device is the character device. A character device delivers or accepts a stream of characters. A keyboard is an example of a character device. If the user types “dog,”, for example, an application would want to read from the keyboard device the d, the o, and finally the g, in exactly that order. A block structure would make little sense and reading/writing characters in any order would also make little sense. Other examples of character devices include rats (for pointing), printers, and network interfaces.
A filesystem is a collection of files and directories organized into a hierarchy. Filesystems (that exist on top of block devices) use the abstraction of blocks for transferring file data to and from storage devices. The smallest addressable unit on a filesystem is a block. Blocks are power-of-two multiple of sector sizes. The most common block size on Linux is 4 KB. Inside the kernel, all I/O operations happen at the granularity of blocks. If an application requests 32 bytes, the kernel must transfer a block from the underlying storage (block) device. The same is true for writes. Everything with regards to storage I/O happens at the block granularity.
The usage of the term “block” is overloaded in the study of computer systems. The context clarifies it. For example, a physical block on a disk drive refers toa sector, and is different from a filesystem block (multiple of sector size). Historically, disk drives are called block devices and not sector devices.
If an application performs partial block operations, i.e., reading and writing less than the block size, this results in an inefficiency. The operating system needs to do extra work to make things happen at the block boundary. On the other hand, user-space applications operate in terms of high-level abstractions, such as, structs and arrays and strings, whose size is typically much smaller than the block.
There is one more issue with small I/O requests, e.g., requesting a single byte from a device. Each such request results in a system call, and too many system calls are bad for performance and slow down applications. Programs that need to issue many small I/O requests typically resort to user-buffered I/O. This type of buffering refers to buffering done in the user space, either manually by the programmer, or transparently in a library. Note that this user-level buffering is on top of the buffering done by the kernel in the page cache. The two serve different purposes!
Discuss with your neighbors or tutor the need for kernel-level buffering and user-level buffering.
Here, we will explore a platform-independent user-buffering solution provided by the standard C I/O library (called stdio). This means that C library routines internally perform buffering of user requests, and only invoke the kernel via system calls for reading/writing blocks. The result is a reduction in the frequency of system calls. The downside of user-level buffering is that there are two copies in addition to the disk transfer. One from the page cache to the standard library buffer and the second from the standard I/O library buffer to the buffer provided by the user (programmer).
Standard I/O library routines do not work directly with file descriptors. They instead use file pointers which are represented by the FILE object defined in stdio.h.
Opening and Reading/Writing File Streams#
Files are opened for reading or writing via fopen():
#include <stdio.h>
FILE * fopen (const char *path, const char *mode);
This function opens the file path with the behaviour given by mode and
associates a new stream with it. The mode argument describes how to open the
give file. The mode argument can be specified as one of the following strings
(reproduced from the man page):
r Open text file for reading. The stream is positioned at
the beginning of the file.
r+ Open for reading and writing. The stream is positioned at
the beginning of the file.
w Truncate file to zero length or create text file for
writing. The stream is positioned at the beginning of the
file.
w+ Open for reading and writing. The file is created if it
does not exist, otherwise it is truncated. The stream is
positioned at the beginning of the file.
a Open for appending (writing at end of file). The file is
created if it does not exist. The stream is positioned at
the end of the file.
a+ Open for reading and appending (writing at end of file).
The file is created if it does not exist. Output is
always appended to the end of the file. POSIX is silent
on what the initial read position is when using this mode.
For glibc, the initial file position for reading is at the
beginning of the file, but for Android/BSD/MacOS, the
initial file position for reading is at the end of the
file.
Once a file stream is opened, you can read from a stream via fread() and write
to a stream via fwrite().
The standard I/O library provides a number of powerful routines for manipulating file data via streams. You should explore the full set of routines here.
Open, compile, and run the program fstream_write.c and fstream_read.c.
Try and determine what the programs are doing before reading on for an
explanation.
In the first program, a new file data.bin is created. We declare a structure
threeNum with three numbers - n1, n2 and n3, and define it in the main
function as num. Inside the for loop we write the value to the file using
fwrite().
The first parameter takes the address of num and the second parameter takes
the size of the structure threeNum. Since we’re only inserting one instance of
num, the third parameter is 1. The last parameter fptr points to the file
we’re writing to. Finally, we close the file.
In the second program, we read from the same data.bin file and loop through
the records one by one. In each iteration of the for loop we read
sizeof(struct threeNum) bytes and store them at the address of num. We print
the values at each iteration.
Exercise 3: Serializing and Deserializing#
The program provided as serialize_linkedlist.c in your lab repository builds a
linked list of student records in memory. The program contains an empty function
serialize_records. The argument filename is the file name that the data
should be written to. Using file stream I/O, write the names and ids to this
file by completing the definition of the serialize_records function.
This process of writing in-memory data structures to a storage-resident file
after eliminating needless meta-data (such as pointers between student records)
is called serialization.
This will be very similar to the code in fstream_write.c, so make sure you
read through and understand that first.
In serialize_linkedlist.c, complete the serialize_records function. Test
by running your program with a destination file argument:
./serialize_records student_data.bin
When serializing a record, why would you not want to serialize the value of the
next pointer? Would this cause problems with deserialization?
The inverse of serialization is deserialization. The file
deserialize_linkedlist.c contains the same record struct definition and
functions for inserting and printing items in the linked list. You will need to
implement the deserialize_records function such that it reads serialized data
from the given file and populates the linked list pointed to by HEAD.
This will be similar to the fstream_read.c code.
Complete the function deserialize_records in deserialize_linkedlist.c. To
test your implementation, check that the linked listed printed after
deserializing from the student_data.bin file is the same as the list printed
by serialise_linkedlist:
./serialize_records student_data.bin
./deserialize_records student_data.bin
Memory-Mapped File I/O#
We will now discuss a second way to perform I/O! This alternative to standard file I/O is to map a file into memory, establishing a one-to-one correspondence between a memory address and a byte in a file. The programmer can then access the file directly through memory, similar to any other memory-resident data. The ability to map disk-backed files into memory is truly phenomenal. It allows direct computation over files via load/store instructions. Let’s see how we can map a storage-backed file into memory!
The mmap System Call#
You should already be familiar with mmap, as it is what you used in your first
assignment. Here we will focus using mmap to read from and write to files.
Linux implements the POSIX-standard mmap() system call for mapping files into memory. mmap() is a system call that can be used by a user process to ask the operating system kernel to map a file into the memory (i.e., address space) of that process. The mmap() system call can also be used to allocate memory (an anonymous mapping), which was the subject of the first assignment. It is important to remember that the mapped pages are not actually brought into physical memory until they are referenced. Therefore, mmap() lazily loads pages into memory (a.k.a., demand paging).
The following figure illustrates the use of the mmap() system call:
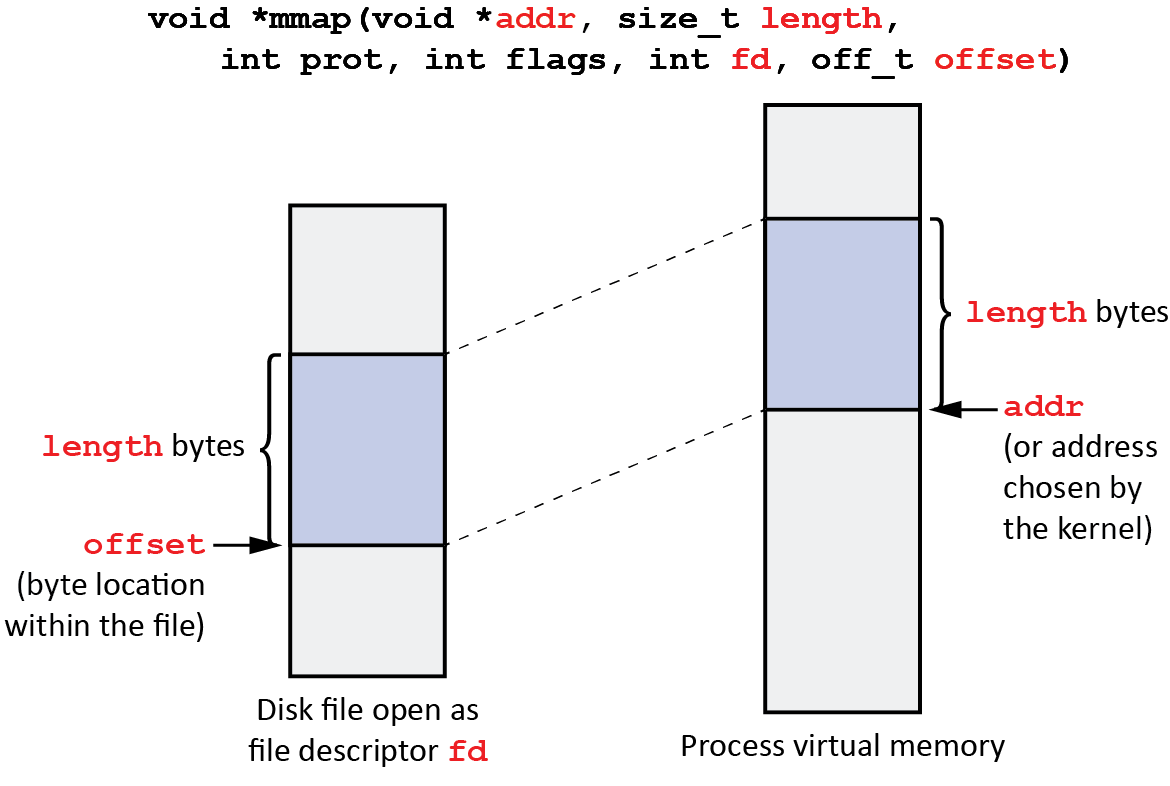
Here is the function prototype for mmap:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
You are (hopefully) already familiar with some of these arguments, but we will explain them here for your benefit anyway:
addr- This argument is a hint to the operating system kernel to use this address at which the virtual mapping should start in the virtual memory (i.e. the virtual address space) of the process. The value can be specified asNULLto indicate that the kernel can place the virtual mapping anywhere it sees fit. If notNULL, thenaddrshould be a multiple of the page size.length- This argument specifies the length as number of bytes for the mapping. This length should be a multiple of the page size.prot- The protection for the mapped memory. The value ofprotis the bitwise or of various of the following single-bit values:PROT_READ- Enable the contents of the mapped memory to be readable by the process.PROT_WRITE- Enable the contents of the mapped memory to be writable by the process.PROT_EXEC- Enable the contents of the mapped memory to be executable by the process as CPU machine instructions.
flags- Various options controlling the mapping. Some of the more commonflagsvalues are:MAP_ANONYMOUS (or MAP_ANON)- Allocate anonymous memory; the pages are not backed by any file.MAP_FILE- The default setting; it need not be specified. The mapped region is backed by a regular file.MAP_FIXED- Don’t interpret addr as a hint: place the mapping at exactly that address, which must be a multiple of the page size.MAP_PRIVATE- Modifications to the mapped memory region are not visible to other processes mapping the same file.MAP_SHARED- Modifications to the mapped memory region are visible to other processes mapping the same file and are eventually reflected in the file.
fd- The open file descriptor for the file from which to populate the memory region. If MAP_ANONYMOUS is specified, thenfdis ignored.offset- If this is not an anonymous mapping, the memory mapped region will be populated with data starting at position offset bytes from the beginning of the file open as file descriptorfd. Should be a multiple of the page size.
On success, mmap() returns a pointer to the mapped area in virtual memory.
On error, the value MAP_FAILED is returned and errno is set to indicate the
reason. You can find full details on the mmap() system call by using the
man mmap command.
The munmap System Call#
munmap is a system call used to unmap memory previously mapped with mmap.
The call removes the mapping for the memory from the address space of the
calling process process:
int munmap(void *addr, size_t length);
There are two arguments to the munmap() system call:
addr- The address of the memory to unmap from the calling process’s virtual mapping. Should be a multiple of the page size.length- The length of the memory (number of bytes) to unmap from the calling process’s virtual mapping. Should be a multiple of the page size.
On success munmap() returns 0, on failure -1 and errno is set to indicate
the reason. If successful, future accesses to the unmapped memory area will
result in a segmentation fault (SIGSEGV).
Advantages of Memory-Mapped I/O#
There are three primary advantages of using mmap() to access files on disk.
- Avoiding needless loading: One advantage of using
mmap()is lazy loading. If no memory within a certain page is ever referenced, then that page is never loaded into physical memory. This can be crucial in certain applications in terms of saving both memory and time. In standard file I/O (or syscall-based I/O), programmers may end up bringing file data that is never used. - Performance: On modern systems, memory mapped I/O is typically faster compared to syscall-based I/O especially for large files. There are at least two sources of speed improvement:
- Eliminating syscall overhead: Traditional I/O involves a lot of system calls (e.g., calls to read()) to load data into memory. We have seen in the lectures that there are costs associated with systems calls, including switching from user to kernel mode, and such costs as error checking within the functions themselves.
- Eliminating copy overhead: Loading data into main memory also has to go through several layers of software abstraction, with the data being copied around in various buffers in the operating system before finally being placed in memory, which clearly will slow down the program. In fact, in the case of user-buffered I/O, there are two copies, one from the kernel page cache to the C library buffer, and another one from the C library buffer to the programmer’s buffer in the application code. Using
mmap()avoids the overheads due to extra copying.
- Programming convenience: Programmers find it convenient to manipulate files using pointers and pointer arithmetic due to its versatility. Also, there is no need for programmers to maintain additional user-level buffers as the operating system manages the buffers in the page cache and returns a pointer to the user.
Let’s see an example of memory-mapped I/O and do some exercises.
Exercise 4: Reading with mmap#
Look at the program mmap_read.c in your repository. This program demonstrates
reading data from a file using mmap. This program calls the open() system
call to open its own source code file (the file mmap_read.c) and then gets the
size (in bytes) of this file using the fstat() system call. The program then
uses mmap() to map that file into the process’s memory, and then prints out
the contents of the file from the memory into which the file has been mapped.
Unfortunately, there are two bugs in the program! Attempting to run this program as-is will cause it to crash.
Find and fix the two bugs in mmap_read.c. Run the program and verify that it
prints the contents of the file correctly.
The first bug you will need to fix is in the call to mmap. Review what each
argument to mmap is and verify whether the argument given in the program is
appropriate.
Exercise 5: Fast Copy#
In the file fast_copy_file.c we provide an incomplete implementation of a
program very similar to the one from Exercise 2. This will take two
a source file name and a destination file name as arguments. The contents of the
source file will be written to the destination file. Instead of using read and
write, fast copy should use mmap and memcpy.
Fill in the rest of the code so that file copying works. You can confirm if
things are working properly by using the Unix/Linux diff command (man diff
will provide the manual page).
You will need to adjust the size of the destination file so that it is large
enough to accept all of the bytes from the source file, with no extra bytes at
the end. You might find ftruncate() useful here.
Complete fast_copy_file.c. Run the program to verify it works.
Compare the amount of time it takes to run fast_copy_file and copy_file on a
large enough file using the command time.
You can use the following command to create a 1MB file filled with (pseudo) random numbers1:
dd if=/dev/urandom of=large_file.bin count=1024 bs=1K
Exercise 6: Modifying Files#
The program modify_file.c provided in the repository maps a file into the
program’s virtual memory. It maps the file with the MAP_PRIVATE flag set and
both read and write permissions enabled.
Modify modify_file.c so that changes made by the program are written back to
the file. Test your program by running it and opening the file ex6-input.txt
to see if the file has changed. Note that you should only need to change the
call to mmap to complete this exercise.
Exercise 7: Word Frequency (Extension)
This is an extension exercise that provides you with very little sample code to start from.
Write a program that reads lines of text from a file on disk and builds a
words data structure in memory. This data structure contains all the unique
words encountered so far, and how many times each occurred. The data structure
appears in memory as follows:

Use the C library function getline to read one line of text at a time. Write
helper functions to handle splitting lines into separate words, inserting them
into the linked list or updating the count of an existing word. Make sure you
take proper care of buffer size for storing the newly read tweet, and for
detecting the end of word, end of line, and end of file.
-
Make sure you don’t add any large files you create to your git repository. ↩