Outline#
- Due date: 13 September 2024, 23:59
- Mark weighting: 20%
- Submission: Submit your assignment through GitLab (full instructions below)
- Policies: For late policies, plagiarism policies, etc., see the policies page
This assignment builds upon the following labs:
If you have not completed the tasks in the above labs or do not understand the content, we strongly recommend that you first complete the labs and then start the assignment.
Introduction#
Managing memory is a major part of programming in C. You have used malloc() and free() in the recent labs. You have also built a very basic memory allocator, and it is now time to build a more advanced allocator.
In this assignment, you will implement a memory allocator, which allows users to malloc() and free() memory as needed.
Your allocator will request large chunks of memory from the OS and efficiently manage all the bookkeeping and memory.
The allocator we ask you to implement is inspired by the DLMalloc allocator designed by Doug Lea. The DLMalloc allocator also inspired the PTMalloc allocator, which GLibC currently uses. Indeed, our allocator is a simplified version of DLMalloc, but you will also notice many similarities.
Background#
We hope that the last two labs have motivated the need for dynamic memory allocators. Specifically, we have seen that while it is certainly possible to use the low-level mmap and munmap functions to manage areas of virtual memory, programmers need the convenience and efficiency of more fine-grained memory allocators. If we managed the memory from the OS ourselves, we could allow allocating and freeing variables in any order, and also reuse memory for other variables.
The last lab taught you how best to build an implicit free list allocator for managing free blocks. In this assignment, we will first build a more efficient free list data structure called an explicit free list, and then perform a number of optimizations.
Explicit free list#
The block allocation time with an implicit free list is linear in the total number of heap blocks which is not suitable for a high-performance allocator. We can add a next and previous pointer to each block’s metadata so that we can iterate over the unallocated blocks. The resulting linked list data structure is called an explicit free list. Using a doubly linked list instead of a free list reduces the first-fit allocation time from linear in the total number of blocks to linear in the total number of free blocks.
Dealing with memory fragmentation#
Fragmentation occurs when otherwise unused memory is not available to satisfy allocate requests. This phenomenon happens because when we split up large blocks into smaller ones to fulfill user requests for memory, we end up with many small blocks. However, some of those blocks may be able to be merged back into a larger block. To address this issue requires us to iterate over the free list and make an effort to find if the block we are trying to free is adjacent to another already free block. If neighboring blocks are free, we can coalesce them into a single larger block.
Dealing with the edges of chunks#
One detail we must consider is how to handle the edges of the chunks from the OS. If we simply start the first allocable block at the beginning of the memory chunk, then we may run into problems when trying to free the block later. This is because a block at the edge of the chunk is missing a neighbor. A simple solution to this is to insert a pair of fenceposts at either end of the chunk. The fencepost is a dummy header containing no allocable memory, but which serves as a neighbor to the first and last allocable blocks in the chunk. Now we can look up the neighbors of those blocks and don’t have to worry about accidentally coalescing outside of the memory chunk allocated by the OS, because anytime one of the neighbors is a fencepost we cannot coalesce in that direction.
Optimizations#
We will also perform the following optimizations as part of the assignment to improve the space and time complexity of our memory allocator.
Reducing the Metadata Footprint#
-
Naive solution: In our description of the explicit free list above, we assume the memory allocated to the user begins after all of the block’s metadata. We must maintain the metadata like size and allocation status because we need it in the block’s header when we free the object.
-
Optimization 1: While we need to maintain the size and allocation status, we only use the free list pointers when the object is free. If the object has been allocated, it is no longer in a free list; thus, the memory used to store the pointers can be used for other purposes. By placing the next and previous pointers at the end of the metadata, we can save an additional 2 * sizeof(pointer) bytes and add that to the memory allocated to the user.
-
Optimization 2: The allocated flag that tells if a block is allocated or not uses only one bit. Since the sizes are rounded up to the next 8 bytes, the last three bits are not used. Instead of using a boolean to store the allocated flag, we can use one of the unused bits in size. That will save an additional 8 bytes.
Constant Time Coalesce#
-
Naive solution: We mentioned above that we could iterate over the free list to find blocks that are next to each other, but unfortunately, that makes the free operation O(n), where n is the number of blocks in the list.
-
Optimized solution: The solution we will use is to add another data structure called Boundary Tags, which allows us to calculate the location of the right and left blocks in memory. To calculate the location of the block to the right, all we need to know is the size of the current block. To calculate the location of the block to the left, we must also maintain the size of the block to the left in each block’s metadata. Now we can find the neighboring blocks in O(1) time instead of O(n).
Multiple Free Lists#
-
Naive solution: So far, we have assumed a single free list containing all free blocks. To find a block large enough to satisfy a request, we must iterate over all the blocks to find a block large enough to fulfill the request.
-
Optimized solution: We can use multiple free lists. We create
nfree lists, one for each allocation size (8, 16, …, 8*(n-1), 8*n bytes.) That way, when a user requests memory, we can jump directly to the list representing blocks that are the correct size instead of looking through a general list. If that list is empty, the next non-empty list will contain the block best fitting the allocation request. However, we only havenlists, so if the user requests8*nbytes of memory or more, we fall back to the naive approach and scan the final list for blocks that can satisfy the request. This optimization cannot guarantee an O(1) allocation time for all allocations. Still, for any allocation under 8*n, the allocation time is O(number of free lists) as opposed to O(length of the free list).
Getting additional chunks from the OS#
The allocator may be unable to find a fit for the requested block. If the free blocks are already maximally coalesced, then the allocator asks the kernel for additional heap memory by calling mmap. The allocator transforms the additional memory into one large free block, inserts the block in the free list, and then places the requested block in this new free block.
Garbage Collector#
A critical pitfall of the malloc/free manual style of memory management is that if the user forgets to free
memory, it results in a memory leak, i.e., memory is consumed even if the block is no longer used or not even reachable by the program.
The garbage collector (GC) is an alternative to manual freeing that takes this burden off the user by automatically figuring
out if allocations are still being used, and freeing those which are not (i.e., dead memory). You will implement what is called a “conservative
mark-and-sweep GC” in this assignment.
Basic idea#
The basic idea is simple. The program has a bunch of variables which it can access directly by name which we call the roots. The roots consist of local variables as well as global variables (though for simplicity we will ignore the latter for this assignment). These roots can then be pointers to objects on the heap, which may themselves be pointers, and so on. Any object which cannot be reached by a series of pointer dereferences starting from the roots is unreachable and hence garbage, and can safely be deallocated. Meanwhile, if an object IS reachable, then it may still be used later in the program and we cannot free its memory.
Our GC will be a function that frees all blocks that do not contain any reachable objects. The GC consists of two phases: mark and sweep. In the mark phase, we start from the roots and look for pointers to locations on the heap. If we find a pointer that points to a location within a block on the heap, we “mark” that block as reachable by changing a flag in the header (similar to the allocated flag). Once done, we then go through and free all of the allocated blocks that were not marked in the “sweep” phase.
The mark flag can be implemented as one of the unused bits at the end of the size parameter in your header.
Modifying malloc and free#
Your malloc and free will need to be modified a bit so that they maintain a data structure tracking the allocated blocks and the locations of their headers. The reasons are twofold:
- In the mark phase, if you have a pointer to the middle of a block, you will need to then find the header of the block in order to set the mark flag. This can be done by going through all the allocated block headers and choosing the one corresponding to the block containing the pointer’s location.
- In the sweep phase, you need to go through each of the allocated blocks when freeing the unmarked ones.
One way is to keep next/prev pointers in the headers of allocated blocks and having your malloc/free maintain a “used list”, similar to the free lists you’ve used so far. Of course, this uses extra metadata, and you need to go through all of the allocated blocks just to find the header of a single one. You are encouraged to use a better approach if you can think of one.
Conservative GC#
Now, the idea of an “object” in C is quite loose, and there are two problems:
- Any value can be cast to a pointer and dereferenced. So even if a variable is of type
int, it has to be treated as a pointer. - A pointer points to a single location in memory, but using pointer offsets we could also access nearby locations. E.g. if the pointer points to an array we’d access the elements of that array via offsets. Given a pointer, you can’t tell where the object pointed to begins and ends.
This is why we will make our allocator “conservative”, which means that it may fail to free some blocks which are actually garbage, but it will never free a block which may be used. In practice:
- When checking the local variables/roots for pointers we scan the entire stack, casting all word-aligned values to pointers (as any of them may be interpreted as pointers).
- When a pointer to a block is found, we don’t just check the value being pointed to but all other word-aligned values in that block for further pointers (as those values can be accessed by offsets from the original pointer).
In order to have a more “precise” GC, you need more support from the programming language and the compiler to provide constraints on what objects can be and how you define them, which allows things like having metadata inside the objects themselves so that we can mark individual objects rather than blocks. GCs in practice tend to be built into the programming language itself, such as in Java. You may learn more about this if you take a compiler course in future.
Lab Specification#
Malloc spec#
You can read the malloc interface on the malloc man page. Many details are left up to the library’s authors. For instance, consider the many optimizations we mention above. All versions of malloc would be correct by the specification on the man page, but some are more efficient than others.
Our implementation spec#
We have described the basic implementation we want you to follow with optimizations in the background and optimization sections above. We now provide the technical specification of the required design. Some of the requirements are in place to enforce conformance to the design, and others guarantee determinism between our reference allocator and your allocator for testing. The specification below should contain all the details necessary to ensure your implementation is consistent with the reference implementation.
Data structures and constants#
We provide certain constants namely:
ARENA_SIZE: We always get a constant chunk of 8 MB from the OS for allocation. For objects larger than 8 MB, you may have to use a multiple of 8 MB.kAlignment: We require word-aligned addresses from our allocations.kMinAllocationSize: We set the minimum allocation size for our allocator to be 1 word.kMaxAllocationSize: We set the maximum allocation size for our allocator to be 32 MB - size of your meta-data. Note you will have to define this constant yourself in yourmymalloc.cfile (like from labs).
Allocation#
- An allocation of 0 bytes should return the NULL pointer for determinism.
- All chunks requested from the OS should be of size
ARENA_SIZEdefined in mymalloc.h. - All requests from the user are rounded up to the nearest multiple of 8 bytes.
- The minimum request size is the size of the full header struct. Even though the pointer fields at the end of the header are not used when the block is allocated, they are necessary when the block is free, and if space is not reserved for them, it could lead to memory corruption when freeing the block.
- When allocating from the final free list (
N_LISTS - 1), the blocks are allocated in first-fit order: you will iterate the list and look for the first block large enough to satisfy the request size. Given that all other lists are multiples of 8, and all blocks in each list are the same size, this is not an issue with the other lists. - When allocating a block, there are a few cases to consider:
- If the block is exactly the request size, the block is simply removed from the free list.
- If the block is larger than the request size, but the remainder is too small to be allocated on its own, the extra memory is included in the memory allocated to the user and the full block is still allocated just as if it had been exactly the right size.
- If the block is larger than the request size and the remainder is large enough to be allocated on its own, the block is split into two smaller blocks. We could allocate either of the blocks to the user, but for determinism, the user is allocated the block which is higher in memory (the rightmost block).
- When splitting a block, if the size of the remaining block is no longer appropriate for the current list, the remainder block should be removed and inserted into the appropriate free list.
- When no available block can satisfy the user’s request, we must request another chunk of memory from the OS and retry the allocation. On initialization of the library, the allocator obtains a chunk from the OS and inserts it into the free list.
- In operating systems, you can never expect a call to the OS to work all the time. If allocating a new chunk from the OS fails, your code should return the NULL pointer, and
errnoshould be set appropriately (check the man page). - The allocator should allocate new chunks lazily. Specifically, the allocator requests more memory only when servicing a request that cannot be satisfied by any available free blocks.
Placement policy#
As we know already, when an application requests a block of k bytes, the allocator searches the free list for a free block that is large enough to hold the requested block. Placement policy dictates the manner in which the allocator performs this search. There are three popular policies.
- First fit: Search the free list from the beginning and choose the first free block that fits.
- Next fit: Similar to first fit, but start each search where the previous one left off.
- Best fit: Examine every free block and choose the free block with the smallest size that fits.
In your assignment, you only need to implement first fit, though the tests won’t fail if you use a different policy.
Deallocation#
- Freeing a NULL pointer is a no-op (don’t do anything).
- When freeing a block, you need to consider a few cases:
- Neither the right nor the left blocks are unallocated. In this case, simply insert the block into the appropriate free list
- Only the right block is unallocated. Then coalesce the current and right blocks together. The newly coalesced block should remain where the right block was in the free list
- Only the left block is unallocated. Then coalesce the current and left blocks, and the newly coalesced block should remain where the left block was in the free list.
- Both the right and left blocks are unallocated, and we must coalesce with both neighbors. In this case, the coalesced block should remain where the left block (lower in memory) was in the free list.
- When coalescing a block, if the size of the coalesced block is no longer appropriate for the current list, the newly formed block should be removed and inserted into the appropriate free list. (Note: This applies even to cases above where it is mentioned to leave the block where it was in the free list.)
my_freeshould behave gracefully (i.e. not crash) when given obviously invalid memory addresses. For the purposes of this requirement an invalid memory address is one that your allocator could not have plausibly returned from a call tomy_malloc.
Garbage collection#
- Garbage collector uses a modified version of
mallocthat creates a “used list” or other data structure to track allocated blocks, potentially using extra metadata in blocks to do so. Yourfreewill also need to remove blocks from this data structure. - Garbage collection is a function that can be called by the program anytime, like “free” except you don’t need to tell it what to free (it will figure it out by itself)
- GC’s mark phase scans the entire stack and considers any word-aligned value in the stack as a pointer
- You are already provided a function
get_end_of_stack()that returns a pointer to the end of the stack, and there is also a global variablestart_of_stackwhich you can assume has been pre-initialised to the start ofmain()’s stack frame. The use of these two is demonstrated in the template file for GC that you’re provided. - GC ignores global variables and variables stored in registers
- If a pointer to a block is found, the entire block is scanned for further pointers
- GC is resistant to circular references and mark phase does not re-scan a block that it’s already scanned. E.g. if block 1 contains a pointer to block 2, which contains a pointer back to block 1, your mark phase must not fall into an infinite loop.
- When sweeping/freeing unused blocks, garbage blocks are removed from the used list (or analogous data structure) and added to the appropriate free lists, and the same rules for coalescing described for
freeare applied.
Tasks#
Your task is to implement malloc (memory allocator) and include in your implementation the various requirements and optimizations discussed above. Broadly, your coding tasks are three-fold.
Allocation#
- Calculate the required block size.
- Find the appropriate free list to look for a block to allocate.
- Depending on the size of the block, either allocate the full block or split the block and allocate the right (higher in memory) portion to the user.
- When allocating a block, update its allocation status.
- Finally, return the user a pointer to the data field of the header.
Deallocation (Freeing)#
- Free is called on the same pointer that
mallocreturned, which means we must calculate the location of the header by pointer arithmetic. - Once we have the block’s header freed, we must calculate the locations of its right and left neighbors, using pointer arithmetic and the block’s size fields.
- Based on the allocation status of the neighboring blocks, we must either insert the block or coalesce it with one or both of the neighboring blocks.
Managing additional chunks#
Handle the case where the user’s request cannot be fulfilled by any of the available blocks.
Note that the tests we provide will succeed even if you submit an mmap or an implicit free list allocator. The success of these provided tests on a non-explicit free list allocator does not mean you are done. Do not submit code files with allocators from a previous lab. We have tests to ensure compliance with the assignment specification.
Garbage Collection#
- Modify malloc and free to maintain additional data structures your GC needs
- Iterate from the beginning to the end of the stack. For each value in the stack, find if that value is an address to a location inside an allocated block. If such a block is found, set its mark flag.
- Recursively scan each block marked in step 2 for pointers to further blocks until no more blocks can be marked.
- Go through all allocated blocks and call
freefor any remaining unmarked blocks.
Report#
You must submit a report of 500-1000 words along with your malloc implementation. The report consists of the following sections.
- Describe your implementation of explicit free list, fence posts, and constant time coalescing. Briefly mention key data structures and function names.
- Describe the optimizations you have attempted in your implementation of malloc.
- If you implemented the garbage collector, discuss that as well.
- Discuss two implementation challenges you encountered in your implementation of malloc.
- Discuss two key observations from testing and benchmarking your malloc implementation. Did something break? Did you end up fixing some stuff after testing and benchmarking? What did not work?
Write your report in markdown format in a file called report.md in the top-level repo. The CI will automatically create a PDF including this report too, which is discussed later. You should check to make sure your report renders correctly as a PDF.
Marking#
The code is worth 60% of your grade (in your specific category). The report is worth 40% of the grade.
Note that having appropriate code style will contribute a small amount to your code mark. This means you should:
- Have clear names for functions and variables
- Have comments explaining what more complex functions do
- Remove any commented out code before submission
- Remove excessive whitespace
- Make sure you only use the
LOGmacro to print things to stdout/stderr.
Coding and Implementation#
Fork the Assignment 1 repo and then clone it locally.
mymalloc.h#
This file contains the type signatures of my_malloc and my_free and some pre-defined constants. Do not change this file. This is especially important as the CI tests will use the original copy of the mymalloc.h file.
mymalloc.c#
This file will contain your implementation of the my_malloc and my_free functions. We only provide some constants to help with your implementation. Your task will be to implement an explicit free-list allocator. We recommend using a modular approach with judicious use of helper functions as well as explanatory comments. You can insert logging calls with the LOG() macro we provide. Its use is the same as printf except it will print the logs to stderr and will not print logs unless you build with logging enabled.
We recommended using exit(1) instead of abort() if you want to stop the execution of the program. We advise to do so because some tests will compare the output directly and using abort() may change the output.
mygc.h#
This file contains type signatures for some additional functions that are described immediately below. Also do not change this file.
mygc.c#
This file will contain your implementation of my_malloc_gc and my_free_gc, the modified versions of my_malloc and my_free to add extra elements to facilitate the GC, as well as your implementation of my_gc, the garbage collector.
You are recommended to first copy in your implementations of my_malloc and my_free from the main C files, as well as
any constants and helper functions you had defined there. We also provide the function get_end_of_stack() and the external
variable start_of_stack (which we will set at the beginning of our test functions to correspond to the start of stack) to give you the endpoints of the stack for convenience.
mygctest.c#
A file with a template main() function where you can insert calls to your GC and test that it frees garbage, avoids freeing reachable blocks, and so on. You are advised not to modify the initialisation of the start_of_stack variable in this file and use the provided my_calloc_gc. Add whatever you want in this file otherwise for testing your GC.
Note that if you define your tests in seperate functions in this file and call those functions in main(), then because the GC includes all functions in the call stack when scanning the stack, it will include any variables you defined in main() when scanning. So be careful of that.
test.py#
Script for testing your implementation.
./test.py -h
usage: test.py [-h] [-t TEST] [--release] [--log] [-m MALLOC]
options:
-h, --help show this help message and exit
-t TEST, --test TEST test name to run
--release build in release mode
--log build with logging
-m MALLOC, --malloc MALLOC
allocator name, default to "mymalloc"
The most important option is -t <TEST> which allows you to test your implementation with a single test.
tests/#
Directory with test source files and built executables. Some tests in this directory also contain explanations of what the test is doing, and potential reasons you may be failing it. You are allowed (and encouraged!) to write your own additional tests and add them to this file.
bench.py#
Script for benchmarking your implementation. The script uses a simple benchmark from the glibc library which stresses your implementation.
usage: bench.py [-h] [-m MALLOC] [-i INVOCATIONS]
options:
-h, --help show this help message and exit
-m MALLOC, --malloc MALLOC
allocator name, default to "mymalloc"
-i INVOCATIONS, --invocations INVOCATIONS
number of invocations of the benchmark
The default number of invocations for the benchmark is 10. If you want to perform quick benchmark runs, then you can change the number of invocations to 3 using -i 3. It is recommended to use at least 10 invocations if you are reporting results, however.
bench/#
Directory with benchmark source files and built executables.
Testing#
You can test your implementation of malloc (assuming you have implemented your allocator in the “mymalloc.c” file) by simply running:
./test.py
The above command will clean previous outputs, compile your implementation, and then run all the provided tests against your implementation. It will run all tests contained in the tests/ folder of your repo. If you want to run a single test (such as align) then you can run the test script like so:
./test.py -t align
If you have another implementation in a different file named “different_malloc.c” (for example), then you can run tests using this implementation with:
./test.py -m different_malloc
This may be useful if you want to test a different implementation strategy or want to benchmark two different implementations (Note: bench.py has this same flag).
Note that while you are allowed to include multiple implementations of the memory allocator in different files, only the one in mymalloc.c will be used when running the CI tests.
If you have inserted logging calls using LOG(), then you can compile and run tests with logging enabled like so:
./test.py --log
Note that some tests which compare output may fail if logging is enabled!
If you want to run a single test directly (for example align) then you can run it like so:
./tests/align
If you have logging enabled and want to save the log for a particular test (for example align) to a file then you can run the following:
./tests/align &> align.log
Make sure you don’t accidentally add the log file to your git repo as these can get quite large in size!
You will almost certainly require using gdb at some point to debug your implementation and failing tests. You can run gdb directly on a test (for example align) like so:
gdb ./tests/align
By default the tests and your library are built with debug symbols enabled so you don’t have to fiddle with enabling debug symbols to aid your gdb debugging.
Testing the GC#
The test.py script does not include tests for the GC, but you can write your own tests in mygctest.c if you’d like. Compile your tests with make mygctest and run ./mygctest. You may put in assert statements, printf statements or whatever you want as part of these tests.
There will be additional test cases we use when marking your code that are not given to you in the assignment repository for both mygc and mymalloc.
Benchmarking#
Note that in this version of the assignment we’ve removed the component where you need to report about the performance of your malloc. However, the scripts for benchmarking are still provided for testing purposes, and for your own exploration if you feel like it.
If you want to benchmark your code, then you will have to install some python libraries, namely numpy and scipy. This can be achieved by using pip3, python’s package manager:
pip3 install numpy scipy
This will install the two libraries to your local user (as opposed to system-wide). This is the recommended method for installing per-user packages for python.
Benchmarking your code works in a similar way as testing:
./bench.py
This will run the provided benchmark (glibc-malloc-bench-simple) from glibc 10 times and provide you the average. If you are benchmarking, it is highly recommended to close all other intensive applications on your machine as you may get random interference otherwise. If you want to report your benchmark numbers, it is important to note what CPU and memory speed you were using in your report.
Just like the test script, you can switch the malloc implementation using the -m <MALLOC> flag. This is useful as you may want to have two different implementations that you want to compare performance on.
Submitting your work#
Submit your work through Gitlab by pushing changes to your fork of the assignment repository. A marker account should automatically have been added to your fork of the Assignment 1 repo (if it isn’t there under “Members” then let one of your tutors know).
We recommend maintaining good git hygiene by having descriptive commit messages and committing and pushing your work regularly. We will not accept late submissions.
Submission checklist#
- The code with your implementation of malloc in
mymalloc.c. - The code with your implementation of the GC in
mygc.c - The
report.mdis in the top-level directory. - (Optional) Any optional tests and benchmrks you want us to look at.
- Your
statement-of-originality.mdhas been filled out correctly.
Gitlab CI and Artifacts#
For this assignment, we provide a CI pipeline that tests your code using the same tests available to you in the assignment repository. It is important to check the results of the CI when you make changes to your work and push them to GitLab. This is especially important in the case where your tests are passing on your local machine, but not on the CI - it is possible your code is making incorrect assumptions about the machine your memory allocator is running on. If you’re failing tests in the CI then it is best to have a look at the CI results for these tests and see if they are giving you hints as to why.
To view the CI pipeline for your repo, click on the little icon to the right of your most recent commit.
![]()

PDF Artifact#
Your repo will be packaged into a pdf for marking purposes. As such it is important that you see what the result
of the pdf job is and make sure the output makes sense.
It will:
- take your name and uid from the
statement-of-originality.md - take the results of the provided CI tests
- take your report written in the
report.mdfile - take test results from the CI
- take references from the
statement-of-originality.md
To view the pdf, first click the ci icon on your most recent commit (as above), then click on the
pdf job.

Then, you’ll be taken to the job page, where you should see a “Job Artifacts” section, click on the Browse button.
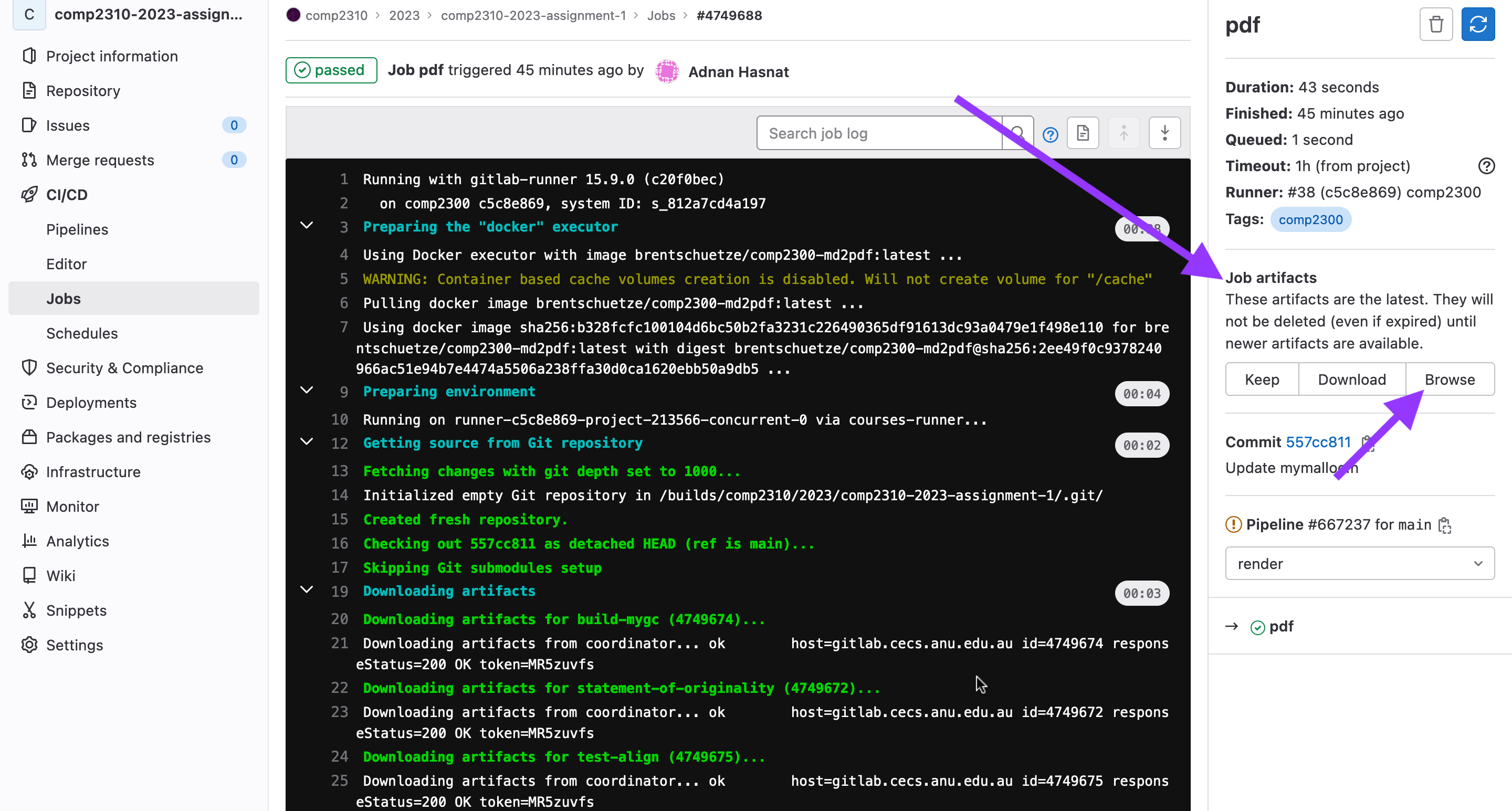
Click on the file to preview what your pdf looks like:
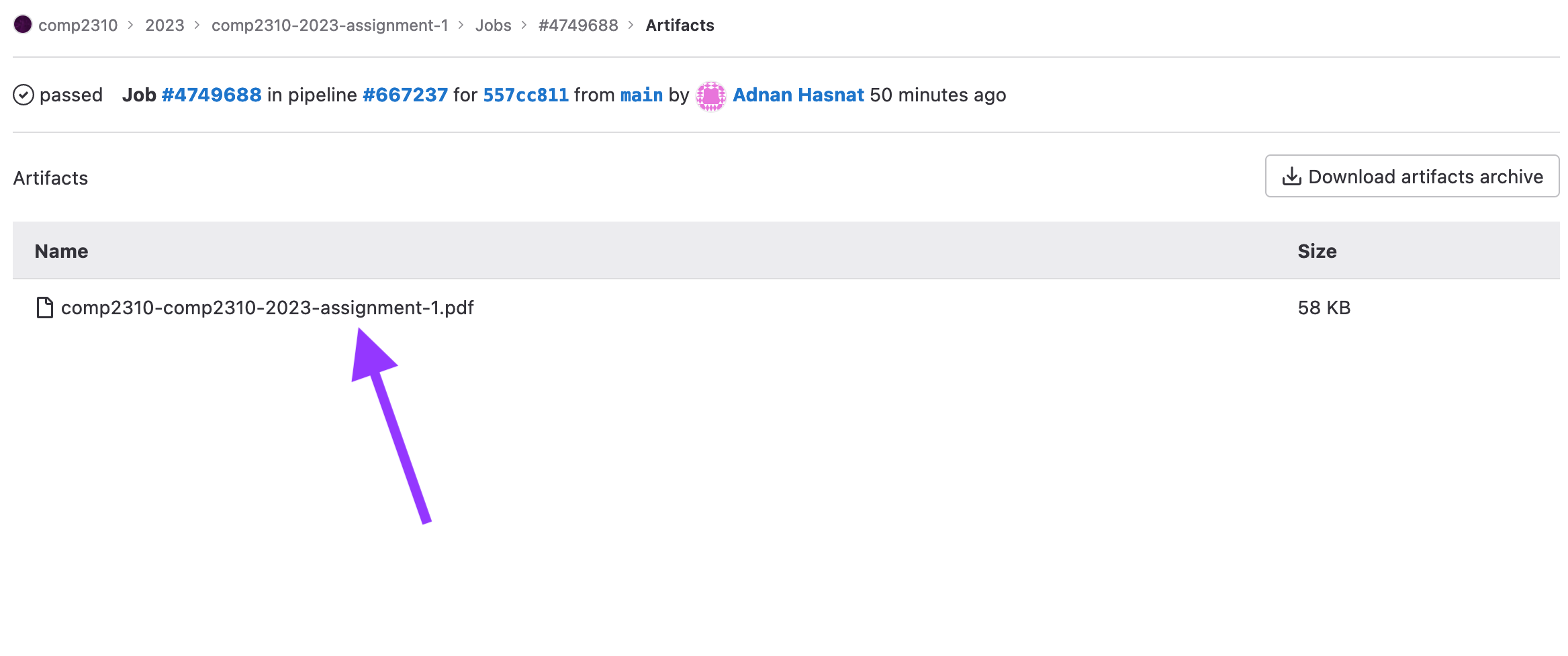
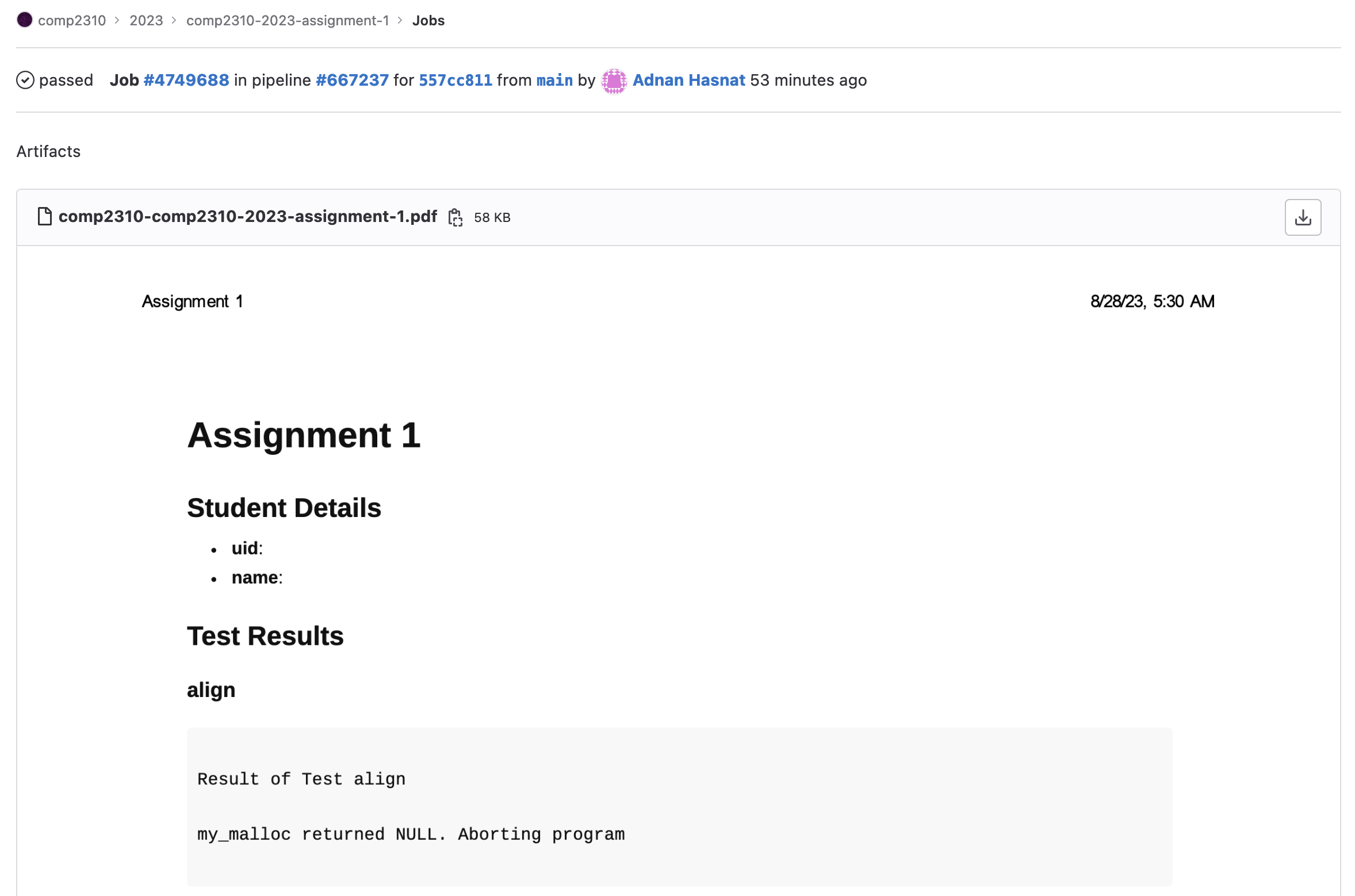
Which should look something like this:
Grading#
The following description of grading categories assumes you submit both the code for your malloc implementation and the report.
Keep in mind that just attempting the given tasks for a grade band is not enough to guarantee you receive a final mark in that grade band. Things like correctness of your implementation, report quality and code style will all influence your results. This is just provided as a guideline.
P#
You will be rewarded a maximum grade of P if you complete the following tasks.
- Implement a single explicit free list
- Linear time coalescing
- Fence posts
CR#
You will be rewarded a maximum grade of CR if you complete the following tasks.
- All tasks in the
Pcategory - Metadata reduction
- Constant time coalescing with boundary tags
- Requesting additional chunks from the OS
D#
You will be rewarded a maximum grade of D if you complete the following tasks.
- All tasks in the
PandCRcategories - Multiple free lists
HD#
You will be rewarded a maximum grade of HD if you complete the following tasks.
- All tasks in the
P,CRandDcategories - The garbage collector