Outline#
In this week’s lab, you will:
- Learn about the C programming toolchain we use in the rest of the course
- Learn to write simple C programs
- Practice using
getchar,putcharandprintffor terminal I/O, as well as command line program arguments - Learn about C pointers, and how to implement pass by reference using them
- Learn to manipulate and handle strings/character arrays
- Learn about function pointers in C
Preparation#
-
Log in with your uni ID/password and open the lab template on GitLab here.
-
Fork the repository by clicking on the fork button. This will create your own copy of the lab repository.
-
Check the URL bar and make sure it contains your uid (eg.
gitlab.cecs.anu.edu.au/*your-uid-here*/comp2310-2023-lab-pack-1). This means you are looking at your copy of the lab, and not the template. Once you’ve done this, click Clone and copy the address next to “Clone with HTTPS”. - Open a terminal and clone with the Git clone command:
git clone address_from_step_3_hereType in your uid and password when requested.
- You should now have a local copy of the repo on your computer. Try moving to the repo’s folder with the
cdandlscommands from earlier.
Congratulations! If you’ve got to this point unscathed, you’ve successfully forked and cloned. You’ll revisit Git later when we cover the add, commit, and push part of using Git - after you’ve made some changes to your lab.
Take your time to familiarize yourself with Git early in the course - you won’t be able to submit the assessment items any other way. We also have videos about using Git on a youtube channel.
Recommended only for lab machines: If you don’t want to type in your uid and password every time you pull and push, you can set up Secure Shell (SSH) keys that authenticate without the need for usernames and passwords. See this page for details. However, use of SSH keys requires either being on campus or connecting through the GlobalProtect VPN.
Before we begin, the first step is to set up the software we use in this course.
- If you are using a lab machine, then congratulations - most of the work has been done already!
- If you are working on your own computer, there are a few different things to install. You can continue reading the lab while the software installs itself. The instructions are on a separate page here.
Introduction#
The C programming language is designed to target a variety of computing hardware and architectures. In almost all desktop computers and laptops, the architecture is x861. We will be teaching the x86 ISA in the first few lectures in this course. As you will be compiling C code to run on either lab machines or your device, the resulting machine code will be for an x86 processor.
Most of the exercises in this lab do not involve writing any substantial code but rather figuring out how things work. We advise that you note down insights and observations as you do the exercises below, as the resulting knowledge will be helpful in later assessments.
Exercise 1: The Toolchain#
Since you are writing high-level C programs that run on a real CPU, we require a standard system for compiling code: a toolchain. The name is derived from the multiple tools used to get from your program to machine code. For our simple projects, the toolchain consists of three main components:
- The compiler is responsible for converting each C file into a machine code file known as an object.
- The linker is responsible for collecting together all of the compiled objects and linking them together into a single executable program.
- The build system is responsible for ‘gluing’ together the individual components to provide a simple interface for compiling your program.
Let us see the toolchain in action. To use the toolchain, first open the C file src/hello_world.c.
Have a quick read of the file contents. What do you think this program will do?
Open up a new terminal in VS Code (Menu Bar -> Terminal -> New Terminal) and run the command,
make hello_world
If you see
make: *** No targets specified and no makefile found. Stop.
Then reopen VS Code with the lab1 folder specifically.
If you see another error, go back and complete the [software setup](/courses/comp2310/resources/software-setup/) steps or look over the troubleshooting tips.
The above make command will trigger the compiler, building the program. If it worked then you should see a new file hello_world in the root lab1 folder. Next run,
make clean
This will remove the output of the previous compilation.
Open the file Makefile in your lab folder and have a look through. We do not expect you to be able to write a makefile! However, you should be able to identify a few components. Can you find the commands from earlier? A few other lines of interest include:
CCspecifies the C compiler to use. We’re using the GNU Compiler Collection (GCC), which will automatically use the linkerldas needed.CFLAGSspecifies options to the compiler. Later in the course we will modify these options.-march(machine architecture) explicitly tells the compiler what CPU architecture to target.-Wall(warnings all) enables many of the compiler’s warning messages (though not all of them, despite the name).-Wconversionenables a type conversion warning (see the Types section).-gtells the compiler to generate debug symbols. This is extra information bundled into the executable file that is used by a debugger to correlate the machine code to your program files. Quite handy when you are trying to find out where your code is wrong!
Run
make hello_world
once again to compile your program. The command creates an executable file called hello_world.
This time, run your compiled code (a.k.a. the executable) in the terminal with,
./hello_world
The ./ tells the terminal that you want to run an executable file in the current working directory (i.e., the lab1 folder).
If everything has worked correctly, the following message should appear in your terminal,
Hello, world!
To speed up the process, you can combine the commands in to one:
make hello_world && ./hello_world
Exercise 2: C Introduction#
The C programming language was developed at Bell Labs by Dennis Ritchie in 1970s. It entered the scene when AT&T was developing the Unix operating system. It quickly rose to prominence as one of the most popular programming languages, a crown that it still holds today. C is notably the first choice for writing low-level software (called systems software), e.g., the Linux operating system.
Systems software interacts closely with the underlying hardware, e.g., for controlling the CPU and memory-resources. High-level user applications (e.g., Spotify) are typically written today in Python and Java. The focus of (user) applications is to provide specific functionality to the user and not to control and manage hardware resources.
Nevertheless, there remains a high demand for C, particularly in embedded systems and IoT and other highly resource constrained environments.
A defining feature of C is that it is closely tied to the underlying hardware. C statements map efficiently to machine instructions. Furthermore, the language is small and simple, leading to efficient code that runs fast and has a small footprint (e.g., the number of instructions).
Therefore, C programs are lightweight compared to other programming languages, such as Java and Python, but are still written at a higher level of abstraction than assembly programs. We will learn in coming labs that C programmers still have low-level access to hardware resources and memory in particular. This last aspect of C is both a blessing and a bane. (You will find out!)
In this half of the course, we intend to teach you how programs written in C interact with CPU and memory at the microarchitectural level. We do not intend to teach programming practices in general and every tiny detail about C’s syntax. We advise you to use the recommended textbook and numerous external online resources for help (when needed).
Every programming language has certain elements critical to writing programs of decent complexity. This tutorial will go through the ones most relevant to the future labs and the second assessment.
Most students in this course have previous programming experience with Java, which has a lot of basic syntax which is similar but is in actuality quite different to C. Think about how C is different from Java as you read the text below.
Variables and basic types#
Declaring variables in C is almost identical to Java, where you have a “type” and then a variable name, and optionally an initial value. Then you can use and modify those variables later in the program as usual.
int foo; // declared variable, not initialised
int bar = 3; // declared and initialised variable
foo = bar + 2;
Also notice how lines of code have to be seperated by semicolons, again same as Java. C is also not whitespace sensitive so any kind of indenting works as long as the semicolons are there to seperate lines, but good code style demands that you indent with caution!
Note that in Java, the compiler would stop you from using a variable without initialising it like below, but although it may raise a warning, C actually doesn’t stop you from doing this! However, it is undefined behavior and the variable can contain any random value before you use it. So best not.
int foo;
int bar = foo + 2; // will raise an error in Java, but not in C
C’s primitive types mostly mirror Java’s primitive types, and include:
| Type | Meaning |
|---|---|
char |
8 bit signed integer |
short |
16 bit signed integer |
int |
32 bit signed integer |
long |
64 bit signed integer |
float |
single-precision real number |
double |
double-precision real number |
You might notice the lack of booleans and strings. C deals with the same sort of objects that most computers do, namely characters, numbers, and memory addresses. Booleans in particular are represented by ints where 0 means false and any non-zero number means true, which will be elaborated on later. The string type will also be discussed later, though you’ve already seen the use of a string literal; the "Hello, world!" text in src/hello_world.c defines a C string.
If you are interested in what ‘single-precision’ and ‘double-precision’ refer to, then look at the IEEE 754 floating-point number specification.
All of the integer types above can have unsigned prepended to them to make them unsigned integers. For example
int x = -3; // x is signed
unsigned int y = 5; // y is unsigned
The floating-point types are always signed.
The C compiler uses types to know how much space in memory to use for a value and how operations on that value work. For example, we can add two ints fine
int x = 1;
int y = 2;
int z = x + y; // 3
But we get possibly unexpected results when adding integer and floating-point types
int x = 1;
double f = 2.7;
int z = x + f; // 3
double q = x + f; // 3.7
In the above example, we add x and f in two different contexts: one assigns the result to an int variable, and the other assigns the result to a double variable. The resulting values from the two operations are different.
In this case, the result is being implicitly converted to the result variable’s type (an “implicit cast”). The C standard defines the rules these conversions follow, so correct programs are allowed to do this. However, it is easy to do this accidentally and not realise it, with the mistake causing errors later on in your program. We have added the -Wconversion flag to our compiler flags to make the compiler show a warning when an expression like the one above may result in lost information. In this case, the compiler would show something like
src/example.c: In function 'main':
src/example.c:7:15: warning: conversion from 'double' to 'int' may change value [-Wfloat-conversion]
7 | int z = x + f; // 3
| ^
As a general rule, it is safe to add values and store the result to the ‘larger’ type. For example,
int i = 1;
long l = 2;
// Warning: conversion from 'long' to 'int' may change value.
// A long is 64 bits, while an int is 32 bits. There are many
// more unique long values than there are possible int values.
int r = i + l;
// No issue: all ints can be converted to longs without data loss.
// For example:
// 0x12345678 -> 0x0000000012345678 (positive)
// 0x87654321 -> 0xFFFFFFFF87654321 (negative)
long s = i + l;
Alternatively, if you do an explicit cast using the cast operator like below, then the compiler knows the cast is intentional and does not warn you. You must know what you’re doing though!
long l = 2;
int i = (int) l
Read and predict what compiler warnings related to type conversion will be raised by src/types.c. Also, add any other type combinations that you find interesting.
Next, compile the program and compare the outcome against your predictions.
make types
There are more C types, which we will discuss later.
There is also a special operator in C which we would like you to know. The sizeof() operator gives the size of a variable in bytes. It is used as follows:
int x = 3;
int s = sizeof(x); // s contains size of x
What will s be in the above code fragment?
Functions#
We can also define functions with syntax identical to Java, including a function signature with the return type, function name and function arguments with types, and then the function body in curly braces:
int sum(int a, int b) {
return a + b;
}
A function that returns nothing has return type void.
All executable C programs have a main function which is the entry point of the program. C files need not contain one if they just define library functions which will be used in other programs (see upcoming discussion of Header files), but generally they do. One possible signature for main is:
int main() {
// statements here...
return 0;
}
The “int” that is returned is the exit code of the program. “0”, the standard code, means the program exited normally. Other exit codes may indicate that an error has occurred, and typically the specific number is used to describe specifically what caused the termination so the programmer can debug problems. Some more status codes are described here.
We will see an alternative signature for the main function and talk about its interface in detail later.
Calling a function is done in the same way as Java as well:
int result = sum(5, 3);
printf#
The C library provides several useful functions for programmers. The printf function prints its arguments on the standard output, which by default is the screen. Unlike most functions you will come across in C, the printf function takes a variable number of arguments. The first argument is always the message to print (such as "Hello, world!"). The remaining arguments are data to be substituted into the message. These arguments can be of any type with a corresponding format specifier. The name printf itself is a combination of print and formatted.
A format specifier begins with %. For example, %i is the ‘integer format specifier’. If you use this format specifier, then the printf call must have an integer value passed as the next argument.
Format specifiers are matched with printf arguments in order from left to right:
- the first format specifier is expanded to the value of the second
printfargument, - the second format specifier is expanded to the value of the third
printfargument, - and so on.
A message does not require format specifiers. You can see this in the src/hello_world.c source file, where only the message to be printed is passed. You will see examples of using format specifiers in the following exercises.
Common format specifiers are as follows
| Format | Meaning |
|---|---|
%% |
Print a single literal %. Necessary to print, e.g., %i literally instead of as a format specifier. All literal % signs should be written like %% in a format string for safety. Note this does not get matched with an argument. |
%c |
Print a char value in ASCII |
%i |
Print int value in decimal |
%x |
Print int value in hexadecimal |
%li |
Print long value in decimal |
%g |
Print floating-point value |
%s |
Print the contents of a char * string (see Arrays) |
%p |
Print pointer value (see Pointers) |
You will also notice that the message often ends with \n. The compiler turns \n into the newline character. If we forget to put a \n at the end, then whatever is printed next will be put on the same line.
So if you see things like
Hello, world!The program has ended[user@host lab1]$
you might be forgetting to add newlines
Hello, world!
The program has ended
[user@host lab1]$
src/format_strings.c shows some examples of using printf to print different types of variables. The last two lines with strings and pointers have not been introduced to you yet, but you can see them here in any case.
Build and run the program:
make format_strings && ./format_strings
Does it print what you expect? Are there any differences?
Other format specifiers and even modifiers can be applied to the given format specifiers. This reference page shows you all the possible values, with examples. The %li format specifier in the table above is an example of a modifier: the l modifies the i format to accept long (64-bit) values instead of 32-bit.
Headers#
Some programs become very large and unmanageable in a single source file. Furthermore, some programs are written to be reused across multiple projects. Copy/pasting code across projects makes it hard to keep code up to date, and thus reusing code inevitably leads to multiple source code files. We need a way to ‘link’ these independent program files together during compilation.
The canonical way to support multiple files in C is with header files. These files are given the .h extension, and they define the signatures of all functions exported from the corresponding .c source file.
You have already seen a .h file be used in the previous examples: stdio.h is a header file in the C standard library that defines the printf function signature (stdio is short for standard input / output). We write #include <stdio.h> to import these signatures into our program, allowing us to use them. Then, when we run the compiler, the linker includes the associated implementation of printf into our compiled program.
#include is called a preprocessor directive, which behaves as if you replaced it with the contents of the specified file at the exact same location. We will often include the <stdio.h> and <stdlib.h> headers to access the functions declared in those headers, which we can then call from our programs. The <stdio.h> contains the declarations for C standard I/O functions. I/O stands for Input/Output. The <stdlib.h> header contains utility functions we will use in future labs.
Anatomy of a C Program#
Return now to your src/hello_world.c file. You should now understand the whole file as written. This basic format will remain the same across your C projects. Line by line, the file contains:
#include <stdio.h>
Includes the stdio.h header that allows use of functions within the stdio (part of the C library). This is required for the printf function.
int main() {
Is the declaration of the main function, the starting point of your program. int is the return type of the function.
printf("Hello, world!\n");
This line calls the printf function, printing the argument to the standard output or stdout, which you see in the terminal.
return 0;
This statement ends the function. Returning 0 is the usual way to signal that the program has terminated without error.
}
C uses {} braces for code bodies, () for function arguments, and ; for line terminations. Here we are closing the code body of the main function.
At this point, you can start writing complete C programs. We encourage you to write a small program or two in src/exercise2.c to practice using printf. Try to print the size in bytes of different C variable types using the sizeof() operator.
Exercise 3: Control flow and simple I/O#
Bitwise and Logical Operators#
You will perhaps remember the bit manipulation you had to do in COMP2300 using assembly instructions like and, orr, lsl and lsr. C similarly allows you to consider numbers in binary, and provides the following operators for bitwise manipulation. These can only be applied to integral operands.
| Operator | Meaning |
|---|---|
& |
Bitwise AND |
| |
Bitwise inclusive OR |
^ |
Bitwise exclusive OR |
<< |
Left shift |
>> |
Right shift |
~ |
One’s complement / bitwise NOT (unary) |
You can also freely write numbers in hexadecimal (recall 0x means the following number is hexadecimal),
and print numbers in hexadecimal using the %x format in printf.
int x = 0x4f3e;
printf("%x", x);
Not all C compilers support 0b to write binary numbers (though yours might). printf also doesn’t support printing in binary format. However, by now you should know how to convert hexadecimal to binary in your head; ask a tutor if not.
There are also “logical operations” that are used when treating numbers as booleans.
| Operator | Meaning |
|---|---|
|| |
Logical OR; outputs 1 if either of its inputs are nonzero/true, and 0 otherwise |
&& |
Logical AND; outputs 1 if both of its inputs are nonzero/true, and 0 otherwise |
! |
Logical NOT; outputs 1 if its input is 0, and 0 if input is nonzero |
Traditionally, when using integers as booleans, people just use the numbers 0 (to mean false) and 1 (to mean true). However,
there are many other numbers that integers can be (e.g. 2, or 40000, or -1). The C spec deals with this by treating ALL nonzero numbers as true. So something like 2 && 3 would be interpreted as TRUE && TRUE, and so output 1 which means TRUE.
Note that bitwise operations and logical operations are strictly different!
int x = 12 & 3; // will output 0, as bitwise AND of 12 = 0b1100 and 3 = 0b0011 is 0
int b = 12 && 3; // will output 1, as 3 and 12 are both interpreted as TRUE, and "TRUE AND TRUE" is TRUE
The constant Booleans FALSE and TRUE are implemented as 0 and 1 respectively.
Open the file src/bitwise-and-shifts.c and predict the outcomes of the statements in the program.
Open the file src/bitwise-puzzles.c and write missing code for the functions in the file. Each function involves solving a puzzle with the provided constraints. The comments provide the detail for solving each puzzle including the constraints, such as, which operators to use for each puzzle. Write a main() function to test your code.
Relational Operators#
The relational operators include
| Operator | Meaning |
|---|---|
== |
Equal to |
!= |
Not equal to |
< |
Less than |
> |
Greater than |
<= |
Less than or equal to |
>= |
Greater than or equal to |
Each of these operators return 1 if the specified relationship is true, and 0 if it is false. The result type is int (but
is intended to be interpreted as a Boolean).
Control Flow#
C has the same standard imperative control flow constructs you’re familiar with from Java, in basically the same syntax. We’ll go over these quickly.
If/else statement example:
if (marks >= 80) {
printf("Your Grade : HD\n");
} else if (marks >= 70) {
printf("Your Grade : D\n");
} else if (marks >= 60) {
printf("Your Grade : CR\n");
} else if (marks >= 50) {
printf("Your Grade : P\n");
} else {
printf("Your Grade : F\n");
}
While loop example:
int x = 4;
while (x > 0) {
printf("%i is greater than 0\n", x);
x = x - 1;
}
Recalling how integers represent Booleans, while (1) {} is how you would write an infinite loop.
For loop example:
for (int i = 0; i < 10; i++) {
printf("i = %i\n", i);
}
Switch statement example (note this is equivalent to the if/else ladder above):
switch(marks / 10) {
case 10:
case 9:
case 8:
printf("Your Grade : HD\n");
break;
case 7:
printf("Your Grade : D\n");
break;
case 6:
printf("Your Grade : CR\n");
break;
case 5:
printf("Your Grade : P\n");
break;
default:
printf("Your Grade : F\n");
}
Remember that if a switch case clause doesn’t have a break statement, execution will keep going to also execute the next case’s case! In general you likely want all of your case clauses to have a break statement, but the above code also shows how you can omit the break statement to combine cases.
continue, break and return statements in loops and functions also exist and work as you’d expect as well.
Character type and Input/Output#
C uses char type to store characters and letters. Interestingly, under the hood, the char type is an integer type. C stores integer numbers instead of characters. More specifically, in C, a char variable is stored as one byte in memory with value ranging from \(-128\) to \(127\). To represent characters, the computer must map each integer to a corresponding character using a numerical code. ASCII is the most common numerical code and it stands for American Standard Code for Information Interchange. Take a look at the ASCII table.
The original ASCII defined characters with values from 0 to 127. Later, many countries used the remaining 128 values in a byte to support their local character set, or more symbols. This lead to the possiblility that an email sent from one country could appear corrupted when read in another. The contents were identical, but the computers were picking different (most likely nonsensical) characters to display!
The following code checks to see if a char value is a valid letter from the English alphabet. Note that the condition checks for both lower-case and upper-case letters.
char c = 'M';
if (
(('a' <= c) && (c <= 'z')) ||
(('A' <= c) && (c <= 'Z'))
) {
printf("Valid letter!\n");
}
You might be tempted to write 'a' <= c <= 'z' like Python allows, but in C this would not evaluate as you might expect. It first evaluates 'a' <= c to 0 or 1, and then compares if this is less than or equal to 'z', which is always true! This is why we split the comparisons and join the results with &&.
Checking if c is between the first and last letters works in ASCII because the numerical values of letters are consecutive from a to z and from A to Z (but not from z to A! There is a gap with symbols in between).
The header file ctype.h provides a number of useful utilities to manipulate characters. You can find several resources with a list and description of useful methods. Here is one useful resource.
getchar and putchar#
It is useful to be able to read one character at a time from keyboard. Each time it is called, getchar reads one character from the keyboard. The code
int c = getchar();
reads a character from the keyboard and assigns it to the integer variable c. The function putchar prints a character each time it is called:
putchar(c);
prints the contents of the integer variable c as a character on the screen.
When interacting with your program through a terminal, getchar does not return as soon as you press a key. The character data is available only when the user presses Enter to indicate they are happy with what is typed. Read more here
Practice Writing Utility Functions#
We will now look at two programs that use control flow and character manipulation. But before that, we want to introduce two useful elements for writing cool programs. The first one is another compiler directive, namely #define. The #define directive allows the definition of constant values to be declared for use throughout your code. Consider the code below
#define HIGH 1
#define LOW 0
int main() {
int high = HIGH;
int low = LOW;
printf("High value is %i\n", high);
printf("Low value is %i\n", low);
return 0
}
Once we define HIGH and LOW to be 1 and 0, respectively, we can use them anywhere in the code. Any occurrence of HIGH will be replaced with 1 and LOW with 0. More generally, HIGH is a symbolic constant and 1 is the replacement text. Symbolic constants are useful for defining constants at the start of a program and judicious use can improve code readability.
A useful symbolic constant defined in stdio.h is EOF (end-of-file) and it indicates there is no more possible input to read. Detecting the end of input is useful when reading input characters from the keyboard as we will see shortly.
The standard input (keyboard) is treated as a special file in C. A program can read input from the keyboard until the end-of-file is encountered. A user can indicate end-of-file by typing a special key combination. If you are typing at the terminal and you want to provoke an end-of-file, use Ctrl-D (Linux, macOS), or Ctrl-Z (Windows). The following C program reads input characters from screen and prints them on screen until the end-of-file is typed.
int c = getchar();
while (c != EOF) {
putchar(c);
c = getchar();
}
Note that EOF is not a character and therefore we must use the larger int type for the variable c against which we compare EOF.
Open the file src/copy1.c and carefully read the code. Compile and run the code. Try to write a condensed version of src/copy1.c in src/copy2.c. Hint: You can do an assignment and test a condition as part of the condition condition in the while loop To test the compiled program, make sure to press Enter each time you input a character from the keyboard.
Open the file src/lines.c and carefully read the code. Can you guess what the code is doing? Compile and run the code to test your guess.
Write a program in src/wordcount.c that counts the number of words typed on the standard input (via keyboard). We define the word as follows: a sequence of characters that does not contain a blank or newline. The program terminates when EOF is encountered.
Interlude: Scopes of Variables#
Let it be noted that variables defined inside functions are only visible inside the function. You can also have variables that sit in the “top level” program outside all of the functions, which are global and visible in all functions.
int x;
void func1() {
int y;
// both x and y visible here
}
void func2() {
int z;
// both x and z visible here
}
Control flow statements also define inner scopes in their clauses. For example, a variable defined in an if statement is not visible outside of it:
if (x == 3) {
int y = 2;
}
printf("y: %i", y) // raises compiler error; y not visible outside if
Instead, we need to define the variable outside the if statement and only initialise it in the if statement:
int y;
if (x == 3) {
y = 2;
}
printf("y: %i", y) // this is fine
This is behavior you should be used to from Java.
Exercise 4: Pointers, Arrays and Strings#
Up until now, C has perhaps looked like nothing more than a simple imperative language, but that will all change with pointers and how C directly relies on the user to control memory!
Pointers#
Every type in C has a corresponding pointer type. A ‘pointer’ is C’s terminology for a memory address. Recall that memory is divided into a number of byte or word-sized locations. Each such location has an address. C is unique in that it gives the programmer the ability to manipulate both the address and the contents of any memory location. Therefore, if you have a pointer to a variable, you have the memory address of that variable. Recall in assembly the use of labels. Pointers and labels are similar in the sense that both contain a memory address. C pointers are real variables that exist at run-time (i.e., when the program runs). Learn this statement by heart:
A pointer is a variable that contains the address of a variable.
The syntax for declaring pointer variables is as follows,
int *my_pointer;
Note that we have inserted * between the type (int in this case) and the variable name (my_pointer). Here we have declared that my_pointer is a variable whose value is the memory address of some int variable. The * operator has multiple uses in C. We have just seen a second use above for pointer declaration, and recall the first use was for multiplication.
But we have not initialised this variable with a value. We cannot use it for anything yet, because that would be undefined behaviour, and correct programs do not have undefined behaviour. We can initialise the pointer variable to point to another variable as follows
int x = 5; // x is an int with value 5
// my_pointer is a pointer with the value <the address of x>
int *my_pointer = &x;
Here we have put & before the use of x to get the address of x instead of its value.
OK, so now we have a valid pointer pointing to another variable. What can we do with it? Consider the following program.
int x = 5;
int *p = &x; // shorter name `p` for our pointer
*p = 7; // store `7` at the memory pointed to by `p`
// what value does `x` have?
It is important to note that we have introduced above a third use of the * operator, which is to dereference a pointer. Dereferencing allows us to read or modify the memory at the location pointed to by the pointer (which, remember, is just a variable that holds a memory address).
As we dereferenced p on the left hand side of the assignment, we have used dereferencing to modify the memory pointed to by p. But this memory is of our variable x! We have changed x without using the name x, except for when we initialised p.
Read the file src/pointers.c. Predict the values of x and p that will be printed before and after the dereference step. Then run
make pointers && ./pointers
What do you see as the outcome? Does it match your prediction?
The operator & gives the address of another variable. The operator * is the dereferencing operator; when applied to a pointer, it accesses the object the pointer points to.
Return to src/pointers.c and remove the contents of the existing main program. Then, define 3 variables consecutively inside the main program like so:
int x = 2;
long y = 3;
int z = 4;
Now use the reference operator and %p option in printf to print the addresses of these variables. What do you notice? Recall the sizes of ints and longs in C. What does this mean about how these variables are laid out in memory?
Now try adding a global variable that is defined OUTSIDE the main program in the top level scope, and print its address. What do you notice, and why? (Hint: remember from assembly; where in memory might a function store its local variables, and how may that differ from global ones?)
Pointers represent memory addresses, which are really just numbers. This means you can cast any integer to a pointer,
and while C might give a conversion warning, it will not error. Return to src/pointers.c and write code to read the contents of the address 0 (or any other random address). What happens?
You will learn more about the error you got in the last exercise when you study the operating system and virtual memory in lectures, but for now just understand that you can’t freely access memory like on the Microbit. The memory has to be allocated to your application, e.g. when you define a global variable the compiler knows to allocate memory for it.
Arrays#
An array is a block of consecutive variables or objects of the same type. The declaration below declares an array named marks of 5 integers.
int marks[5];
Array subscripts start at zero in C. The elements of the marks array can be accessed as follows: marks[0], marks[1], marks[2], and so forth. A subscript (enclosed in square brackets) can be any integer constant or expression. In general, the notation marks[i] refers to the i-th element of the array. We refer to i as an array subscript (or index) and the process of accessing a specific element of an array as indexing an array.
The five integers in the marks array are stored next to each other in memory. If the first element of the marks array is stored at an address 0x00000000, then the next element is found at 0x00000004. The 4-byte increment is because each element of the array is an integer and each integer is four bytes in size.
It is possible to initialize an array during declaration. For example,
int marks[5] = {19, 10, 8, 17, 9};
You can also initialize an array like this.
int marks[] = {19, 10, 8, 17, 9};
Here, we haven’t specified the size. However, the compiler knows its size is 5 as we are initializing it with 5 elements. The assignments below change the values of the first (at index 0) and fourth (at index 3) array element from their initial value.
marks[0] = 10;
marks[3] = 11;
There is a strong relationship in C between arrays and pointers. Any operation that can be achieved with indexing can be done with pointers as well. The name of the array is a synonym for the location of the first element. Therefore, a reference to marks[i] can also be written as *(marks+i). The following two C statements are equivalent,
int x = marks[1]; // x contains 10
int x = *(marks + 1); // x still contains 10
In evaluating marks[i], the compiler converts it to *(marks+i) immediately; the two forms are equivalent.
Recall that a pointer variable contains the address of a memory location. The following C statement declares a pointer named pa and initialises it with the address of the first element of the marks array.
int *pa = marks;
Note that pa now points to the first element of the marks array. We show where the pointer pa points to in the figure below.
The C programming language allows pointer arithmetic. This means that we can add an integer to the pointer pa and make it point to any other element of the marks array.
For example, pa+1 points to the second element of the marks array, i.e., marks[1] (see top of the figure). Note that pa, pa+1, and pa+2 contain the addresses of the array elements and not their contents. These remarks are true regardless of the type and size of variables in the marks array. The meaning of adding 1 to a pointer, and by extension, all pointer arithmetic, is that pa+1 points to the next object, and pa+i points to the i-th object after pa.
To obtain the contents of an array element, we need to use the dereferencing (*) operator. Dereferencing is depicted at the bottom of the figure. For instance, *(pa+2) refers to the value stored at the memory address pa+2.
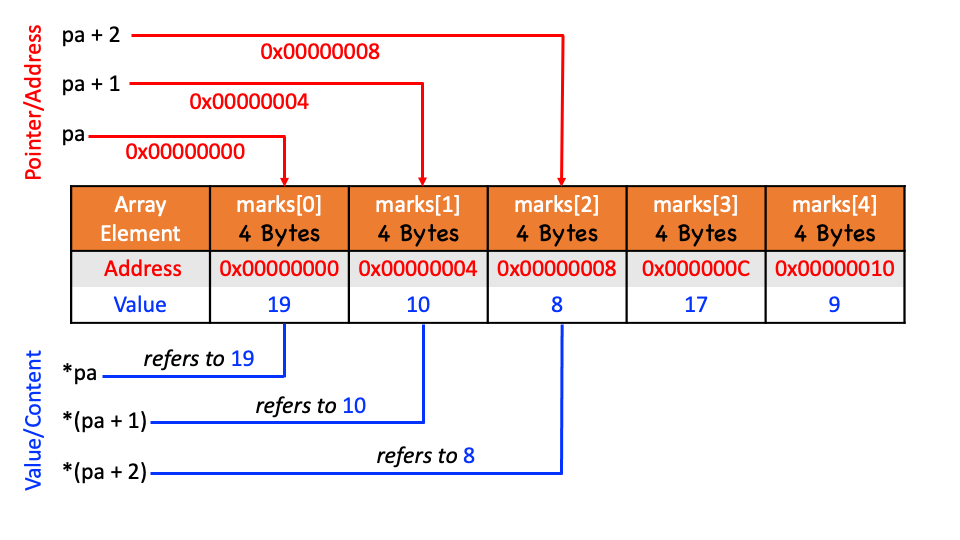 Showing the
Showing the marks array and pointer arithmetic. Each byte in memory has a unique address. Shown above is the starting address of each array element in memory. The array elements are four bytes apart. On the left are shown C expressions for computing the memory addresses (top) and values (bottom).
The following two C statement both print the value of the third element of the marks array,
printf("marks[2] = %d\n", marks[2]); // prints 8 on the screen
printf("marks[2] = %d\n", *(pa + 2)); // prints 8 on the screen
Consider the following two C statements. Their behavior is equivalent.
printf("marks[2] = %d\n", pa[2]);
printf("marks[2] = %d\n", *(pa + 2));
The close relationship between arrays and pointer should now be obvious. Consider the first statement above. We have just indexed the pointer pa to access an element of the array (marks[2])! The compiler knows that we want to access the third integer in the marks array. Similarly, in the second statement, when we add 2 to pa, the result (memory address) points to the third element of the array.
Behind the scenes, when we say pa[2], the compiler multiplies the array subscript by 4 because each array element is four bytes in size in this case. Similarly, when we add 1 to a pointer of type int *, the compiler increments the pointer (memory address) by 4 units instead of just 1 because each integer is 4 bytes in size. Make sure the figure above makes perfect sense and talk to your tutor if you feel confused.
Finally, the following two statements are equivalent and both assign the address of the first element of the marks array to the pointer variable pa.
// assign pa the address of the first element of array
pa = &marks[0];
// array name is a synonym for first element's address
pa = marks;
We often say that arrays decay to pointers. This behavior is especially true when passing arrays to functions as arguments, which we will discuss in a moment.
C does zero bounds checking at runtime; it is very easy to access an index of an array that is beyond the end of its length. This has implications for security as it potentially allows users to access memory they’re not supposed to, as well as program correctness! Most of the time, a segmentation fault will notify you of the error, but sometimes it can be incredibly tricky to debug…
Read the src/arrays.c program and predict the outcome. Then run the program and check if your predictions match the actual outcome. The program should print a warning. Make sure you understand what this warning is about.
make arrays && ./arrays
In src/arrays.c, write a C program where you define an array of integers, and print the address of each element of the array using the subscript ([]) and reference operators (&). Confirm that the elements really are contiguous in memory.
Recall how we described pointer arithmetic. Consider the following code:
int array[] = {1, 2, 3}
int *p = array;
printf("Size of int: %i\n", sizeof(int))
printf("Pointer: %p\n", p);
printf("Pointer plus one: %p\n", p + 1)
printf("Pointer plus two: %p\n", p + 2)
Put this in src/arrays.c, compile and run it. How much does p increment by each time 1 is added? Now try changing all
the instances of “int” in the above code to “char”. Does your answer to the last question change? Why should it?
Controlling pointer arithmetic will be important especially in your first assignment.
C Strings#
Unlike Java, which has a dedicated String object type, strings in C are just arrays of char values. So the following is a C string
char *my_string = "Hello";
When you create a string in this way, the C compiler will automatically write a byte with value 0x00 at the end. The resulting array is called a null-terminated string, and is a method of determining the length of the string without tracking the length in a separate variable. So the above string initialises memory the same in the following way,
char my_string[] = { 'H', 'e', 'l', 'l', 'o', '\0' };
-
Single and double quotes mean different things in C. Single quotes are used to create
charvalues. Double quotes are used to create string values (an array ofcharvalues ending with a null (zero) byte). -
Similar to
\n, the sequence\0is replaced by the C compiler with an actual null byte.
It is not possible to modify a string declared using "..." syntax. Trying to do so is undefined behaviour. It might even work on your computer, but fail on someone else’s.
Open the src/string-util.c file and implement string_cpy and reverse functions. Don’t forget to set the trailing null bytes!
Exercise 5: Pointers as function arguments#
Recall how functions in C look like from the last tutorial. Functions take input arguments and they optionally return a value. C passes arguments to functions by value (affectionately called pass by value or call by value). These phrases mean that when we provide an argument to a function, the value of that argument is copied into a distinct variable for use within the function. Consider the following function that tries to swap two arguments. We call this version of swap the version 1 or v1.
void swap_v1(int a, int b) {
int temp = a;
a = b;
b = t;
printf("a = %i, b = %i\n", a, b);
}
We first safely store a in a temporary local variable called temp. We then do the swapping. Run the program src/swap-v1.c and you will find something strange. Although a and b have been successfully swapped inside the swap function, when we print a and b from the main function, we still see their original (non-swapped) values.
Why do you think this is happening?
We can use pointers to rewrite the swap function. We can use the indirection (*) operator to declare pointers and dereference them. Consider the following prototype of the swap_v2 function
int main() {
int a = 2, b = 3;
swap_v2(&a, &b); // pass the memory addresses of `a` and `b`
}
void swap_v2(int *a, int *b) {
int temp = ...;
}
Passing arguments in the above fashion is called pass by reference. We are not providing the swap_v2 function the actual values of a and b. Instead, we are passing a reference to a and b. In other words, we are providing the swap_v2 function with the memory addresses of a and b.
Open src/swap-v2.c and write the code to swap a and b in the swap_v2 function. Test that your new function definition swaps the input arguments, so even from the main function, when we print a and b, we observe their values swapped. Does your new function work?
Pointers as function arguments serve another important purpose. Recall that C functions can return only a single value. What if we want our functions to return more than one value? We can pass the address of a variable to a function (i.e., pass a pointer as the input argument). The function can then assign a value to the variable pointed-to by the input argument using the dereference operator.
Read the program in src/return2.c. What value of ret1 and ret2 do you expect to see on the screen? Run the program and test your hypothesis.
Open src/sum.c and complete the function definition of the sum function. Make sure it correctly sums up the elements of the input array to the function. Note again that array arguments can be passed to functions as pointers, and we can do the usual pointer arithmetic on these input arguments. So, sum(int *array) is the same as sum(int array[]).
Write a program that compares two strings character-wise and returns a 1 if the two strings are equal. Otherwise, the function returns 0. Write your code in src/strcmp.c. You can rely on the caller to pass null-terminated strings to the str_cmp function.
Write a function that takes a null-terminated string as an input argument. It computes and returns the length of the string. Test your function by writing a C program with a main function. Write the code in src/strlen.c.
Exercise 6: Program Arguments#
Program arguments are a list of values passed to our program when it is run. You have used this when you ran the make command:
make hello_world
runs the program make with the argument hello_world. That is how make knows to build that particular file.
In C, we can get the program arguments from the argc and argv parameters to main. The function signature for main now looks like
int main(int argc, char **argv) {
// statements here...
return 0;
}
The type of the char **argv parameter looks new, but you have seen this type before: it is just two levels of pointer! argv is a pointer to a pointer to a char. If you read the memory pointed to by argv, the value you get is itself a pointer of type char *. If you read the memory where that pointer points, then you get a char value.
But these argv related pointers are not just to single values — both levels of pointer are to arrays of values. So really argv is an array of C strings, which themselves are null-terminated arrays of char values.
Also remember that C arrays do not store their length like you might be accustomed to in Python. This is fine for the C strings, because they end when we see a null byte, but how long is the overall argv array? This is where argc comes in: argc is the number of elements in the argv array. The given names are actually abbreviations:
argc: argument countargv: argument vector- The term vector in the context of programming refers to a resizable array-like structure. The use of ‘vector’ in the name
argvis historic; as you cannot change its size, array is a better description of the actual data structure.
- The term vector in the context of programming refers to a resizable array-like structure. The use of ‘vector’ in the name
So altogether we have an array of string arguments argv, this array having length argc, and each element in the array is a pointer to a null-terminated C string.
In src/exercise6.c, write a program that, assuming there is at least one program argument,
- On the first line prints
There are X argumentswhereXis replaced with the number of program arguments - On the next line, print
The first argument is YwhereYis replaced by the argument at index 0 - Then, if there is more than one argument:
- On the next line, print
The following arguments are - Then print the rest of the arguments (from index 1) on a new line each with the format:
- Z (size: N)where Z is the argument and N is the sizeof that argument
- On the next line, print
- Then, on the next line, print
The total size of the arguments is TwhereTis replaced by the sum of the sizeof the arguments.
Refer back to earlier sections (as needed) for using pointer values and printing formatted strings.
Build and run your program with different arguments. E.g.,
make exercise6 && ./exercise6 first second last
Do you notice something odd?
Exercise 7: Function Pointers#
Function pointers are pointers that point to executable code (typically other functions). They are used to treat functions as regular data. This means that it is possible to define pointers to functions, which can be assigned, placed in arrays, passed to functions, and even returned by functions. Unlike regular pointers, the type of a function pointer is described in terms of a return value and parameters that the function accepts. Declarations for function pointers look as follows:
int (*match)(int *key1, int *key2);
The above declaration means that we can set match to point to any function that accepts two int pointers and returns an integer. If we have a function match_int as below,
int match_int (int *k1, int *k2) {
if (*k1 == *k2) return 1;
return 0;
}
We can set match to point to the above function with the following statement:
match = match_int;
To execute a function referenced by the function pointer, we simply use the function pointer where we would normally use the function itself. For example,
int x = 10;
int y = 12;
int val = match(&x, &y);
Function pointers are useful for encapsulating functions into data structures. Typically, a function pointer is made a member of a data structure, and the pointer is used to invoke one of the many functions based on the type of data that is stored in the data structure. The Advanced Exercises exercise at the end of this handout helps you to explore this use of function pointers further.
Open the file src/reduction.c and read the comments to fill in the missing parts of the code. The compiled code should either reduce the samples array using reduce1 or reduce2 depending on whether the user runs the compiled binary with -r1 or -r2 argument on the command prompt. If you write the code we ask for properly, you will observe the output 55 for -r1, and 3628800 for -r2.
Advanced Exercises#
The following exercises are a little more difficult, however you are still expected to complete them. Ask your tutors if you get stuck.
Write the program tail, which prints the last n lines of its input. By default, n is 5, but it can be changed by an optional argument, so that tail -n prints the last n lines. The program should behave gracefully regardless of the input or the value of n. You can store the lines in a two-dimensional array of fixed size. If the user enters more lines than a threshold, or lines bigger than the maximum length, the program must terminate gracefully. Note that we do not provide you a template for this program. You need to write this program from scratch.
If you already know how
malloc()works, try to make the best use of available memory instead of using a two-dimensional array of fixed size.
The next exercise explores the power of function pointers with a sorting program that either sorts lines input by the user (via keyboard) lexicographically or numerically. Specifically, if the optional argument -n is given, the program will sort the input lines numerically. A sort typically consists of three parts: (1) a comparison that determines the ordering of a pair of objects (e.g., numbers), (2) an exchange that reverses their order, and (3) a sorting algorithm that makes a sequence of comparisons and exchanges until the objects are in a proper order. Note that the sorting algorithm is independent of the comparison and exchange operations, so by passing different comparison and exchange functions to it, we can arrange to sort by different criteria. Let’s explore this decoupling of concerns via function pointers in the exercise below.
Open the source file src/qsort.c. The source code read lines from the input and sorts them lexicographically using the quick sort algorithm. You do not need to understand quick sort to solve this problem, but if you have the time to explore it, that would be great! Run the program and type a bunch of lines and then enter EOF and observe the output. Now, we would like to add the -n option to the program that sorts the lines entered from the keyboard numerically. Write a function called numcmp that takes two input strings and convert them to double types, and returns -1 if the first argument is less than the second argument, and 1 if the first argument is greater than the second argument, and 0 otherwise. You can use the atof utility function to convert a string to a floating point value. If the user enters -n at the command prompt, then the program should compare the input lines numerically. To test numerical sort, you can input one integer per line from the keyborad and then enter EOF. Note that you will need to change the line in the main function that calls quick_sort.
Note that the src/qsort.c program makes use of generic void* pointers. Normally, C allows assignments only between pointers of the same type. A generic pointer in C is declared as a void pointer in C and it can be assigned to a pointer of any type. Once again, generic pointers are useful for implementing data structures, which we will explore in the future.
Extension: Debugging#
So far you have only ran your programs in the terminal, using printf statements to gain insights in to what is happening. Fortunately, VS Code’s debugger has support for C. To get started, open the ‘Run and Debug’ panel and pick the program you want to debug in the drop-down menu. Press the play button, and VS Code will build and run your code through the debugger.
Resources#
-
cppreference: Comprehensive C reference pages. This reference is not a tutorial. It is instead a reference for the entire C language. It contains a lot of content and terminology we do not cover. It is most helpful for reviewing documentation and usage of specific functions, such as
printf. -
codecademy: Free external resource for learning C.
-
x86 is a CISC ISA that originally debuted on the Intel 8086 in 1978. It has since been expanded from 16 to 32, to 64 bits. Featuring variable instruction lengths, over 30 extensions, many addressing modes, and full backward compatibility (16-bit code will run on a modern 64bit processor!), x86 is rightfully considered one of the most complex ISAs to exist. ↩