Outline#
- Due date: 1 November 2024, 11:59 pm
- Mark weighting: 20%
- Submission: Submit your assignment through GitLab (full instructions below)
- Policies: For late policies, plagiarism policies, etc., see the policies page
This assignment builds upon checkpoint 2 and the following labs:
If you have not completed the tasks in the above checkpoint and labs or do not understand the content, we strongly recommend that you first complete the checkpoint and labs and then start the assignment.
Introduction#
Distribution is the key to scalable web services. For example, a single host machine is not capable of hosting the massive index spanning the entire world wide web. There is not enough CPU, memory, and storage on a single machine. Therefore, indices are distributed across many nodes and each node serves (responds to) a selection of queries generated by clients (users of a service). In this assignment you will learn to implement a distributed inverted index with optimizations that target improved performance. You will gain insight into the internal working of web serving infrastructures.
There are two types of nodes in this assignment: clients and servers. Clients generate search queries. Queries consist either of a single term (word) or multiple terms. Querying clients can send a query request to any node. Serving nodes can either serve the request from their local cache or forward the request to a different node. Each node owns a subset of the key space (words in our case). The key space is partitioned statically. Nodes forward requests for words/postings they do not own to other nodes. To avoid forwarding the same request again nodes maintain a local cache of postings and results (explained later).
We provide you a framework with code to start server nodes to which clients can connect and send query requests. Your task is to implement the missing pieces.
Requirements#
Each node contains a subset (partition) of the index. The node can be up (live) or down (dead). The system you build in this assignment must provide the following guarantees:
- All clients see the same data at the same time no matter which (live) node they connect to.
- Any client that requests data from a live node gets a response even if some of the nodes are dead.
- The system continues to function even if there is a communication breakdown between two live nodes.
Typically any distributed key-value store cannot provide all of the above guarantees. Specifically, nodes receive queries (read requests) and updates to the index (write requests) during live operation making it impossible to offer all of the above requirements. In this assignment, we assume that nodes are populated with data and indices are built during an initial ingest phase. After that server nodes only receive read requests, no updates to the data occurs.
We do not fully specify how you deliver the above properties. For example, if a node is down, you can respond with cached results (see below for caching) of the same query received earlier or respond with a graceful failure message.
System Overview#
The system you build in this assignment looks like the following diagram:
Here is a visual overview of the two phases, “ingest” and “serve”:
This is an example of the ingest phase for a single node. After the parent process has created all nodes, it awaits for requests from each node for their section of the database. The message each child node sends should be their node id (as a string) followed by a newline. The response the parent submits consists of two things:
- The total size in bytes of the node’s partition (let this be
n), followed by a newline. - After this newline, the next
nbytes are the contents of the partition.
The node reads these n bytes and store the data in memory, and then build the hash table it uses in the serve phase. After this, it can now enter the serve phase:
A node in the serve phase waits for any connections to be made. A client then connects to the node, and will write one or more request lines to the server. The requests are the same as those used in checkpoint two: one or two keys, followed by a newline. For each line the node will write back the results of the query. Once the client has disconnected or sent an EOF indicator, the node has finished serving that client and can resume waiting for other clients to connect.
Lab Specification#
In this assignment a node is equivalent to a process. The setup is a single host machine with multiple client processes and server processes. We provide you a framework with one parent process (main()) that spawns child processes. Each child process serves as a server node. In this assignment, the number of nodes are limited between one and eight (inclusive). The parent process not only creates child processes but also handles setting up of listening file descriptors (and prots) for them.
Data Partitioning#
Each server node first builds the local index partition to be able to serve query requests. The parent process is responsible for partitioning data between nodes. In the ingest phase the parent process waits for each node to send a request for its partition of the dataset. The format of the request is a string representation of node’s identifier followed by newline. The entire inverted index is distributed among nodes using key for partitioning. The first letter of each key is used to partition. All dataset files are sorted alphabetically. Valid keys are ASCII characters from 0 to z (inclusive). We provide you the parent-end of the ingestion phase. Your task is to implement the ingestion-time functionality of the child nodes that includes sending request to parent for data and building the local partial index.
The assignment framework provides code to find the node identifier that a key belongs to. The method we use to partition nodes (dividing up based on first letters of keys) is fairly basic, and can cause nodes to be somewhat imbalanced in the size of their partitions. On the other hand, the simplicity of this method means that it is easy to figure out which node a request needs to be forwarded to (and it is also easy to test).
The following diagram may help illustrate the way the partitioning scheme works:
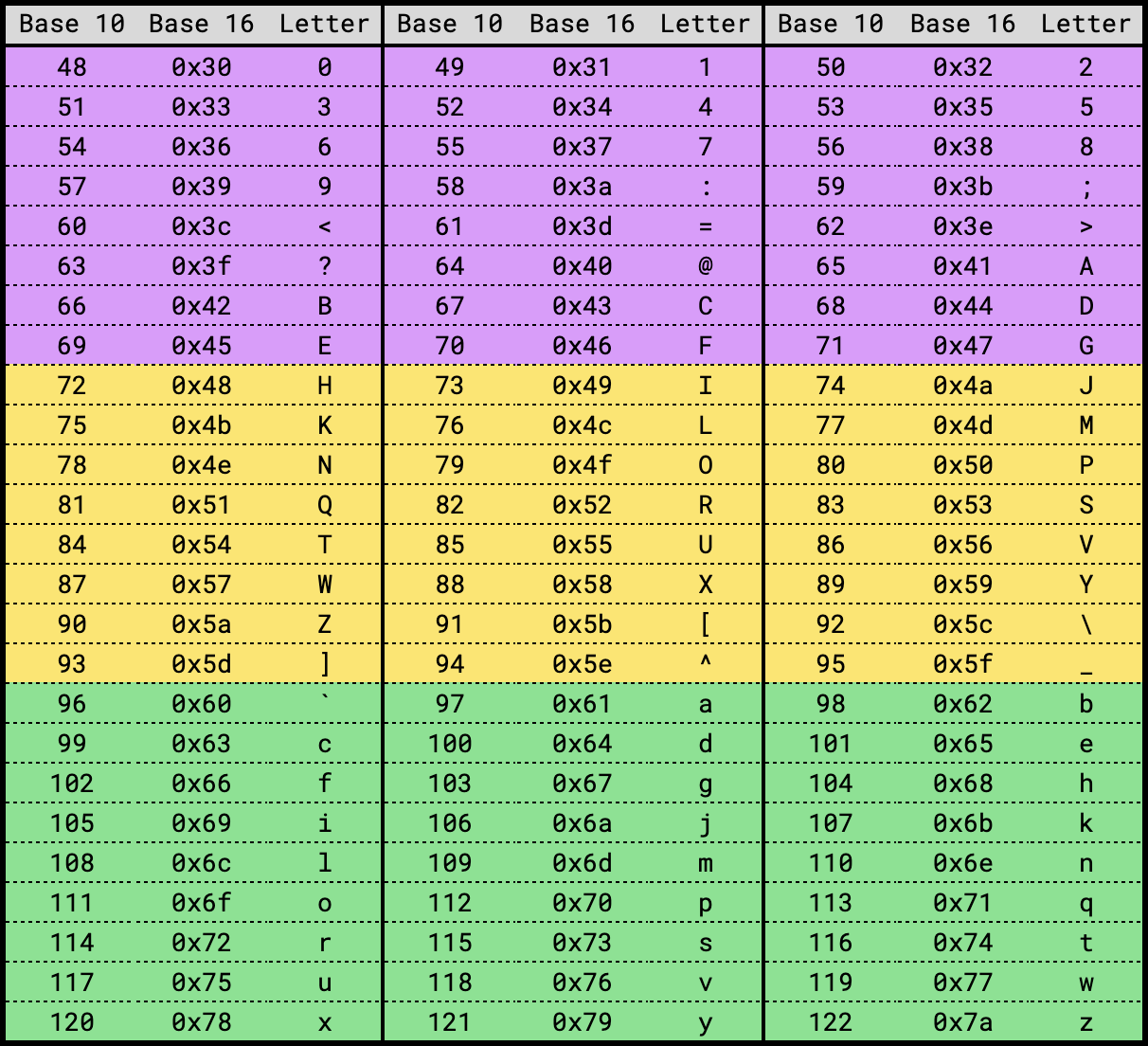
Supposing there are three nodes:
- Node 0 will contain keys that start with a character from ‘0’-‘G’
- Node 1 will contain keys that start with ‘H’-‘_’
- Node 2 will contain keys that start with ‘`’ to ‘z’.
An important thing to note about this partitioning scheme is that some nodes may end up with no data in their partition, depending on the database used and the distribution of keys within.
Building the Index#
Each node builds the partial inverted index. There are different ways to build an index. One way is to write a sequential log of posting lists on disk. Another approach (and what you should do for this assessment) is to store the postings directly in memory. The node then uses an in-memory hash table (dictionary) for fast lookups. The index is built once and then used for serving throughput the lifetime of the program. Therefore, it is paramount to optimize for read performance instead of write (ingest-time) performance.
Your implementation should use a hashing scheme similar to the one from checkpoint 2. The code for building this hash table is provided for you, but if you would like to use your own hashing scheme (especially if you believe you have a more efficient approach) that is also acceptable, provided it still optimizes for read performance.
Query Serving#
From the perspective of the parent process, after sending each node their partition of the database, the parent process has performed its job. It then just waits for any child processes to terminate and reports their status.
Single Node#
The simplest form of the distributed database server is when only a single node is created. In this case, the node will be given the entire database file in the ingest phase from the parent process. This means no requests will have to be forwarded. The code for this will be very similar to the “query” code from checkpoint 2.
Forwarding Requests to Remote Nodes#
When the server node receives a client query, there are several possible scenarios.
- The query is single-term and the term falls in a partition that is owned by the server node.
- The query is single-term and the term falls in a partition that is owned by a remote node.
- The query is two-term and both terms fall in a partition that are owned by the server node.
- The query is two-term and one or both terms fall in a partition that is owned by a remote node.
To handle the scenarios where a server node does not own the partition, it should forward the request to a remote node. Each server node contains a local map that maps partitions to nodes. Similarly, each node should listen and accept connections that deliver requests forwarded from other nodes. In general, there is no distinction between requests coming from clients and ones forwarded from other nodes.
Multithreading#
Once you have a working sequential node that handles one client query at a time, you should alter it to simultaneously handle multiple requests. The simplest way to implement a concurrent server is to spawn a new thread to handle each new connection request. However, this method creates a substantial amount of additional overhead by spawning a new thread for every single request. A better approach, and the one you should implement is to use a thread pool, where threads are spawned only once and will wait for work to be assigned.
- Note that your threads should run in detached mode to avoid memory leaks.
- The
open_clientfdandopen_listenfdfunctions described in the lectures (and included incsapp.h) are based on the modern and protocol-independentgetaddrinfofunction, and thus are thread safe. - You can use the
sbufpackage if needed to implement shared queues that each thread gets connfd’s from.
Caching#
Frequently forwarding requests for the same words is inefficient. Therefore, each server node maintains a local cache of recently-used remote posting lists. When your node receives a posting list from a remote server, it should cache it in memory before performing the intersection/transmitting the result to the client. If another client requests the same query from the same server, your node need not reconnect to the remote server; it can simply reuse the cached object.
Obviously, if your server nodes were to cache all objects that are ever requested, they would require an unlimited amount of memory. Moreover, because some posting lists are larger than others, it might be the case that one giant posting list consumes the entire cache, preventing other posting lists from being cached at all. To avoid those problems, your server nodes should have both a maximum cache size and a maximum cache object (posting list) size.
The cache contains local copies of remote posting lists. The details of cache management are open-ended. Nodes can implement any or a number of replacement policies. Similarly, nodes can cache postings alone or postings and query results (a.k.a. query cache).
Two concrete replacement policies are:
- The first one approximates a least-recently-used (LRU) eviction policy. It doesn’t have to be strictly LRU, but it should be something reasonably close. Note that both reading an object and writing it count as using the object.
- The second one is least-frequently-used (LFU) policy.
Accesses to the cache must be thread-safe, and ensuring that cache access is free of race conditions will likely be the more interesting aspect of this part of the assignment. The easiest way of ensuring a cache is thread safe would be to lock the entire cache each time a thread needs to read from or write to the cache. This is also inefficient! Instead, there is a special requirement that multiple threads must be able to simultaneously read from the cache. Of course, only one thread should be permitted to write to the cache at a time, but that restriction must not exist for readers. As such, protecting accesses to the cache with one large exclusive lock is not an acceptable solution. You may want to explore options such as partitioning the cache, and of course, using Pthreads readers-writers locks. Note that in the case of LRU, the fact that you don’t have to implement a strictly LRU eviction policy will give you some flexibility in supporting multiple readers.
We do not provide code to set up the cache. The easiest way to implement a correct cache is to allocate a buffer for each active connection and accumulate data as it is received from the server. If the size of the buffer ever exceeds the maximum posting list size, the buffer can be discarded. If the entirety of the remote server’s response is read before the maximum posting list size is exceeded, then the list can be cached.
You should implement one cache per node (not per thread!). Once again, global lock on the entire cache is not an efficient solution, and a better approach is to implement more fine grained locking with read/write locks.
Tasks#
We leave it to you to plan your solution. For clarity, below is a proposed workflow:
- Start with a single node (sequential) implementation
- Extend to multiple nodes and add forwarding
- Extend each node to make it multithreaded
- Extend each node to add local caching of remote postings
Note that you can do (3) without (2), but you cannot do (4) without (2). It is also a good idea to plan ahead - it’s a good idea to think about whether functions you rely on when implementing the earlier stages are thread safe even before you start making each node multithreaded, to save having to re-write code later.
Report#
You must submit a report of 500-1000 words along with your implementation. This report should include:
- A high level overview of how your server works, with particular focus on how a single node handles requests.
- A description of the additional features (e.g. multiple nodes and forwarding, multiple threads) you have implemented and how they work.
- A discussion on any important design decisions you made, and how they affect the performance of your server (especially in regards to caching if you have implemented it).
- A brief discussion on observations from testing your code, and any implementation challenges you faced.
Repository#
The structure of the repository is as follows:
src/: This directory contains the source code. You will primarily have to change thenode.cfile to implement this assignment. As you add more features (such as caching), you may want to add extra.cfiles to break up your code.csapp/: This directory containscsapp.handcsapp.c, which you will have seen in the lab.node.c: This is the “main file” for the server. You should put most of the code you write in this file to start with. It will initially contain the code used to spawn nodes and send partitions of the database. There are a few TODOs with instructions to help you get started.utils.c: This file contains useful helper functions you are free to use as needed. This also includes all of the (relevant) code for Checkpoint 2, such as building the hash table for a database, calculating the intersection between two nodes, and turning an entry into a string. We highly recommend using this code rather than your own code from checkpoint 2 (though you are free to do so if you are confident in its correctness).
tests/: This directory contains all the files the testing framework uses to test your code. You should not modify the contents of this directory.expected/: This directory contains the expected output of each test. Do not modify these files.files/: This directory contains the database files used by the tests. These are similar to those from checkpoint 2, but these files all have their contents sorted alphabeticallyoriginals/: This directory is not used to run any tests, but it is included so you can see the original CSV files used to generate each database.queries/: This directory contains the queries used in each test case.
*.run: These files contain parameters of the each test case (how many nodes to create, which files to read queries from, etc). The testing script contains more information about how these files are structured, if you wish to add your own test cases that are compatible with the testing framework we provide.
output/: This directory is created when the testing script is run. Each subdirectory will contain the output of each test.*/response: Each subdirectory will contain a file calledresponsethat contains the result of concatenating all responses the tests send to the nodes together.*/server.out: Each subdirectory will contain aserver.outfile that has the contents of the programs stdout/stderr.
Makefile: The makefile used to build thedb_server. You are permitted to modify this makefile if needed, as long as runningmake allwill still produce a single executabledb_server.run_tests.sh: A bash script to help test your code. It is similar to the one used for checkpoint 2.
Running and Testing Your Code#
You can run the server by running the executable db_server with the following
command line arguments:
./db_server NUM_NODES PORT_NUMBER DB_FILE
NUM_NODES: The number of nodes to spawn. Must be an integer between 1 and 8 (inclusive).PORT_NUMBER: The port number at which the parent process uses as a starting point when assigning listening sockets.DB_FILE: Filepath of the database the parent process will load into memory and distribute between the nodes.
After starting the server, the parent process will print out information about
the child processes it creates (the node id, process id and the port number the
node is listening on). You can then open another terminal and attempt to connect
to one of the nodes directly using a tool like telnet or netcat/nc.
When you are just starting to implement the single node server, running tests
against your code this way may be more helpful than using the testing script, as
you will be able to see the contents of the servers stdout/stderr in real
time.
Testing Script#
The tests will likely not work if you are using Windows due to DOS line endings.
Run the command find tests -type f -print0 | xargs -0 dos2unix -- as well as dos2unix -f run_tests.sh
and dos2unix send_requests.sh to convert all the scripts and testing files to use Unix line endings.
We have also provided a testing script for your code, similar to the one used in
checkpoint 2. This will automatically run several tests against your code. The tests
involve running the server, running netcat sessions to send queries to each of the nodes and
capturing the responses, then checking the responses against an expected file.
The testing script runs the server with a static starting port (which is 3030), and assumes that this port is
usable. It usually should be when running the tests on your local device (and certainly will be on the CI), but
it may not be if you have instances of your server process running that you never terminated. Do ps -ea | grep db_server
to check for running server processes, and if there are any, do pkill db_server to kill them.
Also, the testing script will first try to connect to your server without sending any messages to check if it’s there, and then make another connection to actually send the requests. In some cases, e.g. if your program doesn’t handle clients that don’t send anything correctly or for some other reason terminates immediately after the first connection, it will cause your tests to fail even if it seems to work when you test it manually.
The command to run the script is the same as before:
./run_tests.sh
And we provide the same options as before:
| Option | Behaviour |
|---|---|
-h |
Display usage information and exit. |
-t test |
Run only one test (test is the name of the test to run). |
-v |
Print the contents of stdout and stderr when running tests. |
-n |
Disable color in the testing script output. |
As always, feel free to write additional test cases. Consult the Repository section to see the necessary
files you would need to create, and the below set of options to see how the *.run files are structured:
-n num number of server nodes
-f file path to database to load in ingest phase (path relative to current working directory)
-t queries1,node1,queries2,node2 list of queries files containing requests to be sent to the associated nodes
(queries file paths are relative to the directory tests/queries, so e.g. if
the queries file is tests/queries/queries1 you would pass in queries1)
-p specifies to send each query file's requests in parallel (default is sequential)
-e expected path to file with expected result (path relative to tests/expected)
There are a few requirements of this assignment that the testing script does not explicitly check. For example, it does not check whether you gracefully handle the case where a node dies, or whether you cache contents correctly.
Marking#
The code is worth 80% of your grade. The report is worth 20% of your grade. As with assignment 1, code style will contribute a small amount to your code mark. This includes things like:
- Having clear names for functions and variables
- Having comments explaining what more complex functions do
- Removing any commented out code before submission
- Removing excessive whitespace
- Avoiding leaving an excessive amount of
printfstatements in your code
The breakdown for the code section is as follows:
- A correct implementation of a single node server will result in a mark in the “pass” range
- A correct implementation of (1), and the ability to handle multiple nodes will result in a mark in the “credit” range
- A correct implementation of (1), (2), and the addition of multiple threads able to handle requests in a node will result in a mark in the “distinction” range.
- A correct implementation of all of the above, and the ability to cache requests in nodes will result in a mark in the “high distinction” range. Getting a higher mark in the high distinction range will require not just correctly implementing all requirements, but doing so in an efficient way. This includes (but is not limited to): general code efficiency and quality, and the design decisions you make when implementing the cache (how yor implementation decides when/what to cache, eviction policy, searching the cache, etc).
Keep in mind that “correct” doesn’t just refer to all test cases passing. Your implementation must match the written specification. Remember to read the above very carefully to make sure you haven’t missed anything.
Submission#
Submit your work through Gitlab by pushing changes to your fork of the assignment repository. A marker account should automatically have been added to your fork of the Assignment 2 repo (if it isn’t there under “Members” then let one of your tutors know).
We recommend maintaining good git hygiene by having descriptive commit messages and committing and pushing your work regularly. We will not accept late submissions without an extension.
Gitlab CI and Artifacts#
As with the other assessment items for this course, we provide a CI pipeline that tests your code using the same tests available to you in the assignment repository. It is important to check the results of the CI when you make changes to your work and push them to GitLab. This is especially important in the case where your tests are passing on your local machine, but not on the CI - it is possible your code is making incorrect assumptions about the machine your server is running on. If you’re failing tests in the CI then it is best to have a look at the CI results for these tests and see if they are giving you hints as to why.
Full instructions on how to do so are available on the assessments page for the first assignment